Запись Запросов в ClickHouse с использованием Данных GitHub
Этот набор данных содержит все коммиты и изменения для репозитория ClickHouse. Он может быть сгенерирован с использованием встроенного инструмента git-import, поставляемого с ClickHouse.
Сгенерированные данные предоставляют файл tsv для каждой из следующих таблиц:
commits - коммиты со статистикой.file_changes - файлы, измененные в каждом коммите с информацией об изменении и статистикой.line_changes - каждая измененная строка в каждом измененном файле в каждом коммите с полной информацией о строке и информацией о предыдущем изменении этой строки.
На 8 ноября 2022 года каждый TSV имеет приблизительно следующий размер и количество строк:
commits - 7.8M - 266,051 строкfile_changes - 53M - 266,051 строкline_changes - 2.7G - 7,535,157 строк
Генерация данных
Это необязательно. Мы распространяем данные бесплатно - смотрите Скачивание и вставка данных.
git clone git@github.com:ClickHouse/ClickHouse.git
cd ClickHouse
clickhouse git-import --skip-paths 'generated\.cpp|^(contrib|docs?|website|libs/(libcityhash|liblz4|libdivide|libvectorclass|libdouble-conversion|libcpuid|libzstd|libfarmhash|libmetrohash|libpoco|libwidechar_width))/' --skip-commits-with-messages '^Merge branch '
Это займет около 3 минут (на 8 ноября 2022 года на MacBook Pro 2021) для завершения для репозитория ClickHouse.
Полный список доступных опций можно получить из встроенной справки инструмента.
Эта справка также предоставляет DDL для каждой из вышеупомянутых таблиц, например:
CREATE TABLE git.commits
(
hash String,
author LowCardinality(String),
time DateTime,
message String,
files_added UInt32,
files_deleted UInt32,
files_renamed UInt32,
files_modified UInt32,
lines_added UInt32,
lines_deleted UInt32,
hunks_added UInt32,
hunks_removed UInt32,
hunks_changed UInt32
) ENGINE = MergeTree ORDER BY time;
Эти запросы должны работать на любом репозитории. Не стесняйтесь исследовать и сообщать о своих находках. Несколько рекомендаций относительно времени выполнения (на ноябрь 2022 года):
- Linux -
~/clickhouse git-import - 160 минут
Скачивание и вставка данных
Следующие данные могут быть использованы для воспроизведения рабочей среды. В качестве альтернативы этот набор данных доступен в play.clickhouse.com - смотрите Запросы для получения дополнительных сведений.
Сгенерированные файлы для следующих репозиториев можно найти ниже:
- ClickHouse (8 ноября 2022 года)
- Linux (8 ноября 2022 года)
Чтобы вставить эти данные, подготовьте базу данных, выполнив следующие запросы:
DROP DATABASE IF EXISTS git;
CREATE DATABASE git;
CREATE TABLE git.commits
(
hash String,
author LowCardinality(String),
time DateTime,
message String,
files_added UInt32,
files_deleted UInt32,
files_renamed UInt32,
files_modified UInt32,
lines_added UInt32,
lines_deleted UInt32,
hunks_added UInt32,
hunks_removed UInt32,
hunks_changed UInt32
) ENGINE = MergeTree ORDER BY time;
CREATE TABLE git.file_changes
(
change_type Enum('Add' = 1, 'Delete' = 2, 'Modify' = 3, 'Rename' = 4, 'Copy' = 5, 'Type' = 6),
path LowCardinality(String),
old_path LowCardinality(String),
file_extension LowCardinality(String),
lines_added UInt32,
lines_deleted UInt32,
hunks_added UInt32,
hunks_removed UInt32,
hunks_changed UInt32,
commit_hash String,
author LowCardinality(String),
time DateTime,
commit_message String,
commit_files_added UInt32,
commit_files_deleted UInt32,
commit_files_renamed UInt32,
commit_files_modified UInt32,
commit_lines_added UInt32,
commit_lines_deleted UInt32,
commit_hunks_added UInt32,
commit_hunks_removed UInt32,
commit_hunks_changed UInt32
) ENGINE = MergeTree ORDER BY time;
CREATE TABLE git.line_changes
(
sign Int8,
line_number_old UInt32,
line_number_new UInt32,
hunk_num UInt32,
hunk_start_line_number_old UInt32,
hunk_start_line_number_new UInt32,
hunk_lines_added UInt32,
hunk_lines_deleted UInt32,
hunk_context LowCardinality(String),
line LowCardinality(String),
indent UInt8,
line_type Enum('Empty' = 0, 'Comment' = 1, 'Punct' = 2, 'Code' = 3),
prev_commit_hash String,
prev_author LowCardinality(String),
prev_time DateTime,
file_change_type Enum('Add' = 1, 'Delete' = 2, 'Modify' = 3, 'Rename' = 4, 'Copy' = 5, 'Type' = 6),
path LowCardinality(String),
old_path LowCardinality(String),
file_extension LowCardinality(String),
file_lines_added UInt32,
file_lines_deleted UInt32,
file_hunks_added UInt32,
file_hunks_removed UInt32,
file_hunks_changed UInt32,
commit_hash String,
author LowCardinality(String),
time DateTime,
commit_message String,
commit_files_added UInt32,
commit_files_deleted UInt32,
commit_files_renamed UInt32,
commit_files_modified UInt32,
commit_lines_added UInt32,
commit_lines_deleted UInt32,
commit_hunks_added UInt32,
commit_hunks_removed UInt32,
commit_hunks_changed UInt32
) ENGINE = MergeTree ORDER BY time;
Вставьте данные, используя INSERT INTO SELECT и функцию s3. Например, ниже мы вставляем файлы ClickHouse в каждую из их соответствующих таблиц:
commits
INSERT INTO git.commits SELECT *
FROM s3('https://datasets-documentation.s3.amazonaws.com/github/commits/clickhouse/commits.tsv.xz', 'TSV', 'hash String,author LowCardinality(String), time DateTime, message String, files_added UInt32, files_deleted UInt32, files_renamed UInt32, files_modified UInt32, lines_added UInt32, lines_deleted UInt32, hunks_added UInt32, hunks_removed UInt32, hunks_changed UInt32')
0 rows in set. Elapsed: 1.826 sec. Processed 62.78 thousand rows, 8.50 MB (34.39 thousand rows/s., 4.66 MB/s.)
file_changes
INSERT INTO git.file_changes SELECT *
FROM s3('https://datasets-documentation.s3.amazonaws.com/github/commits/clickhouse/file_changes.tsv.xz', 'TSV', 'change_type Enum(\'Add\' = 1, \'Delete\' = 2, \'Modify\' = 3, \'Rename\' = 4, \'Copy\' = 5, \'Type\' = 6), path LowCardinality(String), old_path LowCardinality(String), file_extension LowCardinality(String), lines_added UInt32, lines_deleted UInt32, hunks_added UInt32, hunks_removed UInt32, hunks_changed UInt32, commit_hash String, author LowCardinality(String), time DateTime, commit_message String, commit_files_added UInt32, commit_files_deleted UInt32, commit_files_renamed UInt32, commit_files_modified UInt32, commit_lines_added UInt32, commit_lines_deleted UInt32, commit_hunks_added UInt32, commit_hunks_removed UInt32, commit_hunks_changed UInt32')
0 rows in set. Elapsed: 2.688 sec. Processed 266.05 thousand rows, 48.30 MB (98.97 thousand rows/s., 17.97 MB/s.)
line_changes
INSERT INTO git.line_changes SELECT *
FROM s3('https://datasets-documentation.s3.amazonaws.com/github/commits/clickhouse/line_changes.tsv.xz', 'TSV', ' sign Int8, line_number_old UInt32, line_number_new UInt32, hunk_num UInt32, hunk_start_line_number_old UInt32, hunk_start_line_number_new UInt32, hunk_lines_added UInt32,\n hunk_lines_deleted UInt32, hunk_context LowCardinality(String), line LowCardinality(String), indent UInt8, line_type Enum(\'Empty\' = 0, \'Comment\' = 1, \'Punct\' = 2, \'Code\' = 3), prev_commit_hash String, prev_author LowCardinality(String), prev_time DateTime, file_change_type Enum(\'Add\' = 1, \'Delete\' = 2, \'Modify\' = 3, \'Rename\' = 4, \'Copy\' = 5, \'Type\' = 6),\n path LowCardinality(String), old_path LowCardinality(String), file_extension LowCardinality(String), file_lines_added UInt32, file_lines_deleted UInt32, file_hunks_added UInt32, file_hunks_removed UInt32, file_hunks_changed UInt32, commit_hash String,\n author LowCardinality(String), time DateTime, commit_message String, commit_files_added UInt32, commit_files_deleted UInt32, commit_files_renamed UInt32, commit_files_modified UInt32, commit_lines_added UInt32, commit_lines_deleted UInt32, commit_hunks_added UInt32, commit_hunks_removed UInt32, commit_hunks_changed UInt32')
0 rows in set. Elapsed: 50.535 sec. Processed 7.54 million rows, 2.09 GB (149.11 thousand rows/s., 41.40 MB/s.)
Запросы
Инструмент предлагает несколько запросов через свой вывод справки. Мы ответили на них в дополнение к некоторым дополнительным вспомогательным вопросам. Эти запросы имеют примерно возрастающую сложность по сравнению с произвольным порядком инструмента.
Этот набор данных доступен в play.clickhouse.com в базах данных git_clickhouse. Мы предоставляем ссылку на эту среду для всех запросов, адаптируя имя базы данных по мере необходимости. Обратите внимание, что результаты игры могут отличаться от представленных здесь из-за различий во времени сбора данных.
История одного файла
Самые простые запросы. Здесь мы рассматриваем все сообщения коммитов для StorageReplicatedMergeTree.cpp. Поскольку они, вероятно, более интересные, мы сортируем по самым последним сообщениям первыми.
play
SELECT
time,
substring(commit_hash, 1, 11) AS commit,
change_type,
author,
path,
old_path,
lines_added,
lines_deleted,
commit_message
FROM git.file_changes
WHERE path = 'src/Storages/StorageReplicatedMergeTree.cpp'
ORDER BY time DESC
LIMIT 10
┌────────────────time─┬─commit──────┬─change_type─┬─author─────────────┬─path────────────────────────────────────────┬─old_path─┬─lines_added─┬─lines_deleted─┬─commit_message───────────────────────────────────┐
│ 2022-10-30 16:30:51 │ c68ab231f91 │ Modify │ Alexander Tokmakov │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 13 │ 10 │ исправить доступ к части в состоянии удаления │
│ 2022-10-23 16:24:20 │ b40d9200d20 │ Modify │ Anton Popov │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 28 │ 30 │ лучшее семантическое заполнение DataPartStorage │
│ 2022-10-23 01:23:15 │ 56e5daba0c9 │ Modify │ Anton Popov │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 28 │ 44 │ удалить DataPartStorageBuilder │
│ 2022-10-21 13:35:37 │ 851f556d65a │ Modify │ Igor Nikonov │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 3 │ 2 │ Удалить неиспользуемый параметр │
│ 2022-10-21 13:02:52 │ 13d31eefbc3 │ Modify │ Igor Nikonov │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 4 │ 4 │ Полировка реплицируемого дерева слияния │
│ 2022-10-21 12:25:19 │ 4e76629aafc │ Modify │ Azat Khuzhin │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 3 │ 2 │ Исправления для -Wshorten-64-to-32 │
│ 2022-10-19 13:59:28 │ 05e6b94b541 │ Modify │ Antonio Andelic │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 4 │ 0 │ Полировка │
│ 2022-10-19 13:34:20 │ e5408aac991 │ Modify │ Antonio Andelic │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 3 │ 53 │ Упрощение логики │
│ 2022-10-18 15:36:11 │ 7befe2825c9 │ Modify │ Alexey Milovidov │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 2 │ 2 │ Обновление StorageReplicatedMergeTree.cpp │
│ 2022-10-18 15:35:44 │ 0623ad4e374 │ Modify │ Alexey Milovidov │ src/Storages/StorageReplicatedMergeTree.cpp │ │ 1 │ 1 │ Обновление StorageReplicatedMergeTree.cpp │
└─────────────────────┴─────────────┴─────────────┴────────────────────┴─────────────────────────────────────────────┴──────────┴─────────────┴───────────────┴──────────────────────────────────────────────────┘
10 строк в наборе. Время выполнения: 0.006 сек. Обработано 12.10 тысяч строк, 1.60 MB (1.93 миллиона строк/с., 255.40 MB/с.)
Мы также можем просмотреть изменения строк, исключая переименования, т.е. мы не будем показывать изменения перед событием переименования, когда файл существовал под другим именем:
play
SELECT
time,
substring(commit_hash, 1, 11) AS commit,
sign,
line_number_old,
line_number_new,
author,
line
FROM git.line_changes
WHERE path = 'src/Storages/StorageReplicatedMergeTree.cpp'
ORDER BY line_number_new ASC
LIMIT 10
┌────────────────time─┬─commit──────┬─sign─┬─line_number_old─┬─line_number_new─┬─author───────────┬─line──────────────────────────────────────────────────┐
│ 2020-04-16 02:06:10 │ cdeda4ab915 │ -1 │ 1 │ 1 │ Alexey Milovidov │ #include <Disks/DiskSpaceMonitor.h> │
│ 2020-04-16 02:06:10 │ cdeda4ab915 │ 1 │ 2 │ 1 │ Alexey Milovidov │ #include <Core/Defines.h> │
│ 2020-04-16 02:06:10 │ cdeda4ab915 │ 1 │ 2 │ 2 │ Alexey Milovidov │ │
│ 2021-05-03 23:46:51 │ 02ce9cc7254 │ -1 │ 3 │ 2 │ Alexey Milovidov │ #include <Common/FieldVisitors.h> │
│ 2021-05-27 22:21:02 │ e2f29b9df02 │ -1 │ 3 │ 2 │ s-kat │ #include <Common/FieldVisitors.h> │
│ 2022-10-03 22:30:50 │ 210882b9c4d │ 1 │ 2 │ 3 │ alesapin │ #include <ranges> │
│ 2022-10-23 16:24:20 │ b40d9200d20 │ 1 │ 2 │ 3 │ Anton Popov │ #include <cstddef> │
│ 2021-06-20 09:24:43 │ 4c391f8e994 │ 1 │ 2 │ 3 │ Mike Kot │ #include "Common/hex.h" │
│ 2021-12-29 09:18:56 │ 8112a712336 │ -1 │ 6 │ 5 │ avogar │ #include <Common/ThreadPool.h> │
│ 2022-04-21 20:19:13 │ 9133e398b8c │ 1 │ 11 │ 12 │ Nikolai Kochetov │ #include <Storages/MergeTree/DataPartStorageOnDisk.h> │
└─────────────────────┴─────────────┴──────┴─────────────────┴─────────────────┴──────────────────┴───────────────────────────────────────────────────────┘
10 строк в наборе. Время выполнения: 0.258 сек. Обработано 7.54 миллиона строк, 654.92 MB (29.24 миллиона строк/с., 2.54 GB/с.)
Обратите внимание, что существует более сложная вариация этого запроса, в которой мы находим историю коммитов строка за строкой файла, учитывая переименования.
Найти текущие активные файлы
Это важно для последующего анализа, когда мы хотим учитывать только текущие файлы в репозитории. Мы оцениваем этот набор как файлы, которые не были переименованы или удалены (а затем повторно добавлены/переименованы).
Обратите внимание, что, вероятно, в истории коммитов произошел сбой в отношении файлов в директориях dbms, libs, tests/testflows/ во время их переименования. Поэтому мы также исключаем их.
play
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)') ORDER BY path
LIMIT 10
┌─path────────────────────────────────────────────────────────────┐
│ tests/queries/0_stateless/01054_random_printable_ascii_ubsan.sh │
│ tests/queries/0_stateless/02247_read_bools_as_numbers_json.sh │
│ tests/performance/file_table_function.xml │
│ tests/queries/0_stateless/01902_self_aliases_in_columns.sql │
│ tests/queries/0_stateless/01070_h3_get_base_cell.reference │
│ src/Functions/ztest.cpp │
│ src/Interpreters/InterpreterShowTablesQuery.h │
│ src/Parsers/Kusto/ParserKQLStatement.h │
│ tests/queries/0_stateless/00938_dataset_test.sql │
│ src/Dictionaries/Embedded/GeodataProviders/Types.h │
└─────────────────────────────────────────────────────────────────┘
10 строк в наборе. Время выполнения: 0.085 сек. Обработано 532.10 тысячи строк, 8.68 MB (6.30 миллиона строк/с., 102.64 MB/с.)
Обратите внимание, что это позволяет файлам быть переименованными, а затем снова переименованными в их первоначальные значения. Сначала мы агрегируем old_path для списка удаленных файлов в результате переименования. Мы объединяем это с последней операцией для каждого path. Наконец, мы фильтруем этот список по тем, где последнее событие не является Delete.
play
SELECT uniq(path)
FROM
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)') ORDER BY path
)
┌─uniq(path)─┐
│ 18559 │
└────────────┘
1 строка в наборе. Время выполнения: 0.089 сек. Обработано 532.10 тысячи строк, 8.68 MB (6.01 миллиона строк/с., 97.99 MB/с.)
Обратите внимание, что мы пропустили импорт нескольких директорий во время импорта, т.е.
--skip-paths 'generated\.cpp|^(contrib|docs?|website|libs/(libcityhash|liblz4|libdivide|libvectorclass|libdouble-conversion|libcpuid|libzstd|libfarmhash|libmetrohash|libpoco|libwidechar_width))/'
Применяя этот шаблон к git list-files, получается 18155.
git ls-files | grep -v -E 'generated\.cpp|^(contrib|docs?|website|libs/(libcityhash|liblz4|libdivide|libvectorclass|libdouble-conversion|libcpuid|libzstd|libfarmhash|libmetrohash|libpoco|libwidechar_width))/' | wc -l
18155
Таким образом, наше текущее решение является оценкой текущих файлов.
Разница здесь вызвана несколькими факторами:
- Переименование может иметь место вместе с другими модификациями файла. Эти события перечислены как отдельные события в file_changes, но с одинаковым временем. Функция
argMax не может их различать - она выбирает первое значение. Естественный порядок вставок (единственное средство для определения правильного порядка) не сохраняется через объединение, поэтому могут быть выбраны модифицированные события. Например, ниже файл src/Functions/geometryFromColumn.h имел несколько модификаций до того, как был переименован в src/Functions/geometryConverters.h. Наше текущее решение может выбрать событие Modify как последнее изменение, что приводит к удержанию src/Functions/geometryFromColumn.h.
play
SELECT
change_type,
path,
old_path,
time,
commit_hash
FROM git.file_changes
WHERE (path = 'src/Functions/geometryFromColumn.h') OR (old_path = 'src/Functions/geometryFromColumn.h')
┌─change_type─┬─path───────────────────────────────┬─old_path───────────────────────────┬────────────────time─┬─commit_hash──────────────────────────────┐
│ Add │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ 9376b676e9a9bb8911b872e1887da85a45f7479d │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ 6d59be5ea4768034f6526f7f9813062e0c369f7b │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ 33acc2aa5dc091a7cb948f78c558529789b2bad8 │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ 78e0db268ceadc42f82bc63a77ee1a4da6002463 │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ 14a891057d292a164c4179bfddaef45a74eaf83a │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ d0d6e6953c2a2af9fb2300921ff96b9362f22edb │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ fe8382521139a58c0ba277eb848e88894658db66 │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ 3be3d5cde8788165bc0558f1e2a22568311c3103 │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ afad9bf4d0a55ed52a3f55483bc0973456e10a56 │
│ Modify │ src/Functions/geometryFromColumn.h │ │ 2021-03-11 12:08:16 │ e3290ecc78ca3ea82b49ebcda22b5d3a4df154e6 │
│ Rename │ src/Functions/geometryConverters.h │ src/Functions/geometryFromColumn.h │ 2021-03-11 12:08:16 │ 125945769586baf6ffd15919b29565b1b2a63218 │
└─────────────┴────────────────────────────────────┴────────────────────────────────────┴─────────────────────┴──────────────────────────────────────────┘
11 строк в наборе. Время выполнения: 0.030 сек. Обработано 266.05 тысяч строк, 6.61 MB (8.89 миллиона строк/с., 220.82 MB/с.)
- Неполная история коммитов - отсутствуют события удаления. Исходная причина должна быть установлена.
Эти различия не должны значительно повлиять на наш анализ. Мы приветствуем улучшенные версии этого запроса.
Список файлов с наибольшим количеством модификаций
Ограничиваясь текущими файлами, мы рассматриваем количество модификаций как сумму удалений и добавлений.
play
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
path,
sum(lines_added) + sum(lines_deleted) AS modifications
FROM git.file_changes
WHERE (path IN (current_files)) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY path
ORDER BY modifications DESC
LIMIT 10
┌─path───────────────────────────────────────────────────┬─modifications─┐
│ src/Storages/StorageReplicatedMergeTree.cpp │ 21871 │
│ src/Storages/MergeTree/MergeTreeData.cpp │ 17709 │
│ programs/client/Client.cpp │ 15882 │
│ src/Storages/MergeTree/MergeTreeDataSelectExecutor.cpp │ 14249 │
│ src/Interpreters/InterpreterSelectQuery.cpp │ 12636 │
│ src/Parsers/ExpressionListParsers.cpp │ 11794 │
│ src/Analyzer/QueryAnalysisPass.cpp │ 11760 │
│ src/Coordination/KeeperStorage.cpp │ 10225 │
│ src/Functions/FunctionsConversion.h │ 9247 │
│ src/Parsers/ExpressionElementParsers.cpp │ 8197 │
└────────────────────────────────────────────────────────┴───────────────┘
10 строк в наборе. Время выполнения: 0.134 сек. Обработано 798.15 тысяч строк, 16.46 MB (5.95 миллиона строк/с., 122.62 MB/с.)
В какой день недели обычно происходят коммиты?
play
SELECT
day_of_week,
count() AS c
FROM git.commits
GROUP BY dayOfWeek(time) AS day_of_week
┌─day_of_week─┬─────c─┐
│ 1 │ 10575 │
│ 2 │ 10645 │
│ 3 │ 10748 │
│ 4 │ 10944 │
│ 5 │ 10090 │
│ 6 │ 4617 │
│ 7 │ 5166 │
└─────────────┴───────┘
7 строк в наборе. Время выполнения: 0.262 сек. Обработано 62.78 тысяч строк, 251.14 KB (239.73 тысячи строк/с., 958.93 KB/с.)
Это имеет смысл с некоторым снижением производительности по пятницам. Приятно видеть, что люди коммитят код в выходные! Большое спасибо нашим контрибьюторам!
История подкаталога/файла - количество строк, коммитов и участников за время
Это приведет к большому результату запроса, который будет нереалистичным для показа или визуализации без фильтрации. Поэтому мы позволяем фильтровать файл или подкаталог в следующем примере. Здесь мы группируем по неделям, используя функцию toStartOfWeek - адаптируйте по необходимости.
play
SELECT
week,
sum(lines_added) AS lines_added,
sum(lines_deleted) AS lines_deleted,
uniq(commit_hash) AS num_commits,
uniq(author) AS authors
FROM git.file_changes
WHERE path LIKE 'src/Storages%'
GROUP BY toStartOfWeek(time) AS week
ORDER BY week ASC
LIMIT 10
┌───────week─┬─lines_added─┬─lines_deleted─┬─num_commits─┬─authors─┐
│ 2020-03-29 │ 49 │ 35 │ 4 │ 3 │
│ 2020-04-05 │ 940 │ 601 │ 55 │ 14 │
│ 2020-04-12 │ 1472 │ 607 │ 32 │ 11 │
│ 2020-04-19 │ 917 │ 841 │ 39 │ 12 │
│ 2020-04-26 │ 1067 │ 626 │ 36 │ 10 │
│ 2020-05-03 │ 514 │ 435 │ 27 │ 10 │
│ 2020-05-10 │ 2552 │ 537 │ 48 │ 12 │
│ 2020-05-17 │ 3585 │ 1913 │ 83 │ 9 │
│ 2020-05-24 │ 2851 │ 1812 │ 74 │ 18 │
│ 2020-05-31 │ 2771 │ 2077 │ 77 │ 16 │
└────────────┴─────────────┴───────────────┴─────────────┴─────────┘
10 строк в наборе. Время выполнения: 0.043 сек. Обработано 266.05 тысяч строк, 15.85 MB (6.12 миллиона строк/с., 364.61 MB/с.)
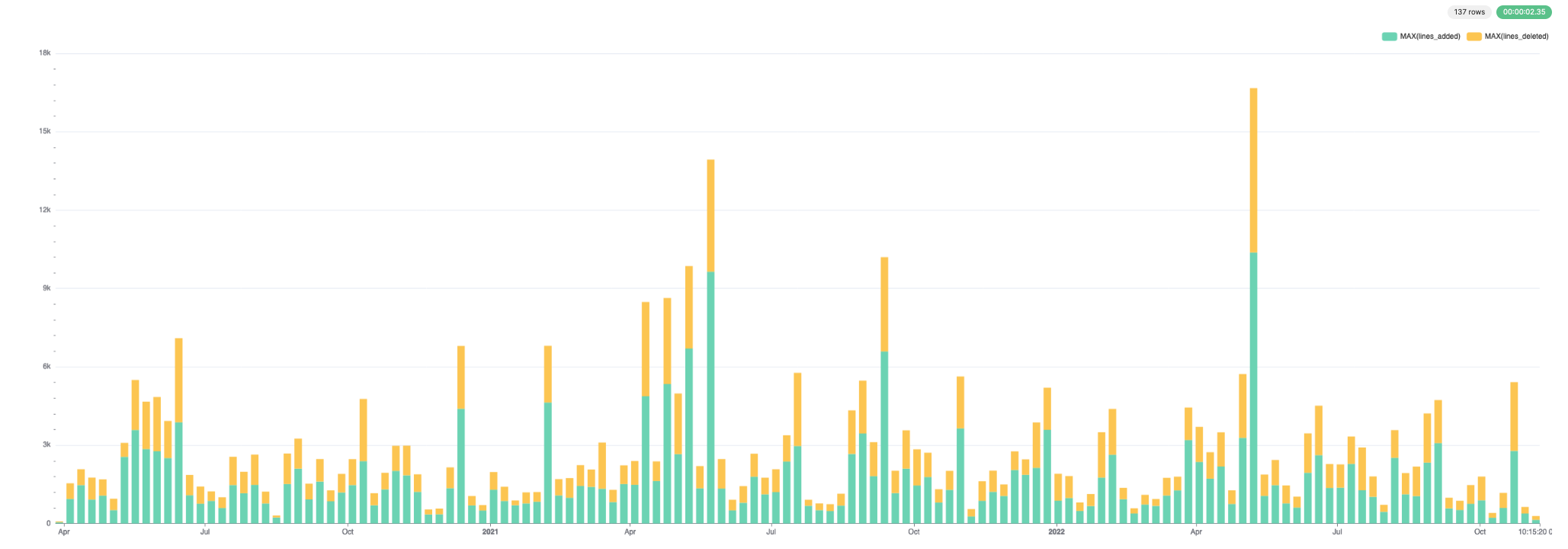
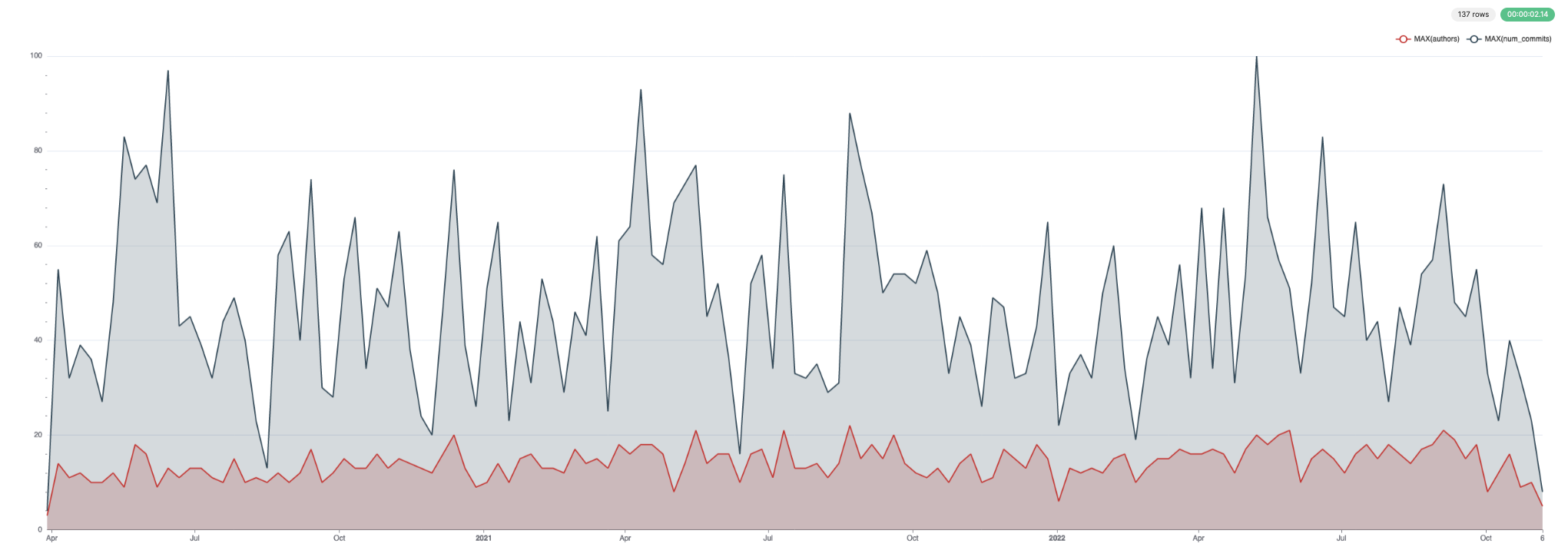
Эти данные хорошо визуализируются. Ниже мы используем Superset.
Для добавленных и удаленных строк:
Для коммитов и авторов:
Список файлов с максимальным количеством авторов
Ограничено только актуальными файлами.
play
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
path,
uniq(author) AS num_authors
FROM git.file_changes
WHERE path IN (current_files)
GROUP BY path
ORDER BY num_authors DESC
LIMIT 10
┌─path────────────────────────────────────────┬─num_authors─┐
│ src/Core/Settings.h │ 127 │
│ CMakeLists.txt │ 96 │
│ .gitmodules │ 85 │
│ src/Storages/MergeTree/MergeTreeData.cpp │ 72 │
│ src/CMakeLists.txt │ 71 │
│ programs/server/Server.cpp │ 70 │
│ src/Interpreters/Context.cpp │ 64 │
│ src/Storages/StorageReplicatedMergeTree.cpp │ 63 │
│ src/Common/ErrorCodes.cpp │ 61 │
│ src/Interpreters/InterpreterSelectQuery.cpp │ 59 │
└─────────────────────────────────────────────┴─────────────┘
10 строк в наборе. Время: 0.239 сек. Обработано 798.15 тысяч строк, 14.13 MB (3.35 миллиона строк/с., 59.22 MB/с.)
Самые старые строки кода в репозитории
Ограничено только актуальными файлами.
play
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
any(path) AS file_path,
line,
max(time) AS latest_change,
any(file_change_type)
FROM git.line_changes
WHERE path IN (current_files)
GROUP BY line
ORDER BY latest_change ASC
LIMIT 10
┌─file_path───────────────────────────────────┬─line────────────────────────────────────────────────────────┬───────latest_change─┬─any(file_change_type)─┐
│ utils/compressor/test.sh │ ./compressor -d < compressor.snp > compressor2 │ 2011-06-17 22:19:39 │ Modify │
│ utils/compressor/test.sh │ ./compressor < compressor > compressor.snp │ 2011-06-17 22:19:39 │ Modify │
│ utils/compressor/test.sh │ ./compressor -d < compressor.qlz > compressor2 │ 2014-02-24 03:14:30 │ Add │
│ utils/compressor/test.sh │ ./compressor < compressor > compressor.qlz │ 2014-02-24 03:14:30 │ Add │
│ utils/config-processor/config-processor.cpp │ if (argc != 2) │ 2014-02-26 19:10:00 │ Add │
│ utils/config-processor/config-processor.cpp │ std::cerr << "std::exception: " << e.what() << std::endl; │ 2014-02-26 19:10:00 │ Add │
│ utils/config-processor/config-processor.cpp │ std::cerr << "Exception: " << e.displayText() << std::endl; │ 2014-02-26 19:10:00 │ Add │
│ utils/config-processor/config-processor.cpp │ Poco::XML::DOMWriter().writeNode(std::cout, document); │ 2014-02-26 19:10:00 │ Add │
│ utils/config-processor/config-processor.cpp │ std::cerr << "Some exception" << std::endl; │ 2014-02-26 19:10:00 │ Add │
│ utils/config-processor/config-processor.cpp │ std::cerr << "usage: " << argv[0] << " path" << std::endl; │ 2014-02-26 19:10:00 │ Add │
└─────────────────────────────────────────────┴─────────────────────────────────────────────────────────────┴─────────────────────┴───────────────────────┘
10 строк в наборе. Время: 1.101 сек. Обработано 8.07 миллионов строк, 905.86 MB (7.33 миллиона строк/с., 823.13 MB/с.)
Файлы с самой длинной историей
Ограничено только актуальными файлами.
play
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
count() AS c,
path,
max(time) AS latest_change
FROM git.file_changes
WHERE path IN (current_files)
GROUP BY path
ORDER BY c DESC
LIMIT 10
┌───c─┬─path────────────────────────────────────────┬───────latest_change─┐
│ 790 │ src/Storages/StorageReplicatedMergeTree.cpp │ 2022-10-30 16:30:51 │
│ 788 │ src/Storages/MergeTree/MergeTreeData.cpp │ 2022-11-04 09:26:44 │
│ 752 │ src/Core/Settings.h │ 2022-10-25 11:35:25 │
│ 749 │ CMakeLists.txt │ 2022-10-05 21:00:49 │
│ 575 │ src/Interpreters/InterpreterSelectQuery.cpp │ 2022-11-01 10:20:10 │
│ 563 │ CHANGELOG.md │ 2022-10-27 08:19:50 │
│ 491 │ src/Interpreters/Context.cpp │ 2022-10-25 12:26:29 │
│ 437 │ programs/server/Server.cpp │ 2022-10-21 12:25:19 │
│ 375 │ programs/client/Client.cpp │ 2022-11-03 03:16:55 │
│ 350 │ src/CMakeLists.txt │ 2022-10-24 09:22:37 │
└─────┴─────────────────────────────────────────────┴─────────────────────┘
10 строк в наборе. Время: 0.124 сек. Обработано 798.15 тысяч строк, 14.71 MB (6.44 миллиона строк/с., 118.61 MB/с.)
Наша основная структура данных, Merge Tree, очевидно, постоянно развивается и имеет длинную историю изменений!
Распределение участников по документации и коду за месяц
Во время захвата данных изменения в папке docs/ были отфильтрованы из-за нечистой истории коммитов. Результаты этого запроса поэтому не точны.
Пишем ли мы больше документации в определенные моменты месяца, например, вокруг дат релизов? Мы можем использовать функцию countIf для вычисления простого соотношения, визуализируя результат с помощью функции bar.
play
SELECT
day,
bar(docs_ratio * 1000, 0, 100, 100) AS bar
FROM
(
SELECT
day,
countIf(file_extension IN ('h', 'cpp', 'sql')) AS code,
countIf(file_extension = 'md') AS docs,
docs / (code + docs) AS docs_ratio
FROM git.line_changes
WHERE (sign = 1) AND (file_extension IN ('h', 'cpp', 'sql', 'md'))
GROUP BY dayOfMonth(time) AS day
)
┌─day─┬─bar─────────────────────────────────────────────────────────────┐
│ 1 │ ███████████████████████████████████▍ │
│ 2 │ ███████████████████████▋ │
│ 3 │ ████████████████████████████████▋ │
│ 4 │ █████████████ │
│ 5 │ █████████████████████▎ │
│ 6 │ ████████ │
│ 7 │ ███▋ │
│ 8 │ ████████▌ │
│ 9 │ ██████████████▎ │
│ 10 │ █████████████████▏ │
│ 11 │ █████████████▎ │
│ 12 │ ███████████████████████████████████▋ │
│ 13 │ █████████████████████████████▎ │
│ 14 │ ██████▋ │
│ 15 │ █████████████████████████████████████████▊ │
│ 16 │ ██████████▎ │
│ 17 │ ██████████████████████████████████████▋ │
│ 18 │ █████████████████████████████████▌ │
│ 19 │ ███████████ │
│ 20 │ █████████████████████████████████▊ │
│ 21 │ █████ │
│ 22 │ ███████████████████████▋ │
│ 23 │ ███████████████████████████▌ │
│ 24 │ ███████▌ │
│ 25 │ ██████████████████████████████████▎ │
│ 26 │ ███████████▏ │
│ 27 │ ███████████████████████████████████████████████████████████████ │
│ 28 │ ████████████████████████████████████████████████████▏ │
│ 29 │ ███▌ │
│ 30 │ ████████████████████████████████████████▎ │
│ 31 │ █████████████████████████████████▏ │
└─────┴─────────────────────────────────────────────────────────────────┘
31 строк в наборе. Время: 0.043 сек. Обработано 7.54 миллиона строк, 40.53 MB (176.71 миллион строк/с., 950.40 MB/с.)
Может быть, немного больше в конце месяца, но в целом мы поддерживаем хорошее равномерное распределение. Опять же, это ненадежно из-за фильтрации папки документации во время вставки данных.
Авторы с самым разнообразным влиянием
Мы считаем разнообразием количество уникальных файлов, к которым автор внес свой вклад.
play
SELECT
author,
uniq(path) AS num_files
FROM git.file_changes
WHERE (change_type IN ('Add', 'Modify')) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY author
ORDER BY num_files DESC
LIMIT 10
┌─author─────────────┬─num_files─┐
│ Alexey Milovidov │ 8433 │
│ Nikolai Kochetov │ 3257 │
│ Vitaly Baranov │ 2316 │
│ Maksim Kita │ 2172 │
│ Azat Khuzhin │ 1988 │
│ alesapin │ 1818 │
│ Alexander Tokmakov │ 1751 │
│ Amos Bird │ 1641 │
│ Ivan │ 1629 │
│ alexey-milovidov │ 1581 │
└────────────────────┴───────────┘
10 строк в наборе. Время: 0.041 сек. Обработано 266.05 тысяч строк, 4.92 MB (6.56 миллиона строк/с., 121.21 MB/с.)
Давайте посмотрим, у кого самые разнообразные коммиты в недавней работе. Вместо ограничения по дате, мы ограничим последний N коммитов автора (в данном случае, мы использовали 3, но не стесняйтесь менять):
play
SELECT
author,
sum(num_files_commit) AS num_files
FROM
(
SELECT
author,
commit_hash,
uniq(path) AS num_files_commit,
max(time) AS commit_time
FROM git.file_changes
WHERE (change_type IN ('Add', 'Modify')) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY
author,
commit_hash
ORDER BY
author ASC,
commit_time DESC
LIMIT 3 BY author
)
GROUP BY author
ORDER BY num_files DESC
LIMIT 10
┌─author───────────────┬─num_files─┐
│ Mikhail │ 782 │
│ Li Yin │ 553 │
│ Roman Peshkurov │ 119 │
│ Vladimir Smirnov │ 88 │
│ f1yegor │ 65 │
│ maiha │ 54 │
│ Vitaliy Lyudvichenko │ 53 │
│ Pradeep Chhetri │ 40 │
│ Orivej Desh │ 38 │
│ liyang │ 36 │
└──────────────────────┴───────────┘
10 строк в наборе. Время: 0.106 сек. Обработано 266.05 тысяч строк, 21.04 MB (2.52 миллионов строк/с., 198.93 MB/с.)
Любимые файлы для автора
Здесь мы выбираем нашего основателя Alexey Milovidov и ограничиваем наш анализ актуальными файлами.
play
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
path,
count() AS c
FROM git.file_changes
WHERE (author = 'Alexey Milovidov') AND (path IN (current_files))
GROUP BY path
ORDER BY c DESC
LIMIT 10
┌─path────────────────────────────────────────┬───c─┐
│ CMakeLists.txt │ 165 │
│ CHANGELOG.md │ 126 │
│ programs/server/Server.cpp │ 73 │
│ src/Storages/MergeTree/MergeTreeData.cpp │ 71 │
│ src/Storages/StorageReplicatedMergeTree.cpp │ 68 │
│ src/Core/Settings.h │ 65 │
│ programs/client/Client.cpp │ 57 │
│ programs/server/play.html │ 48 │
│ .gitmodules │ 47 │
│ programs/install/Install.cpp │ 37 │
└─────────────────────────────────────────────┴─────┘
10 строк в наборе. Время: 0.106 сек. Обработано 798.15 тысяч строк, 13.97 MB (7.51 миллиона строк/с., 131.41 MB/с.)
Это имеет смысл, потому что Алексей отвечает за поддержание Change log. Но что если мы используем базовое имя файла, чтобы определить его популярные файлы - это позволяет учитывать переименования и должно сосредоточиться на вклад в код.
play
SELECT
base,
count() AS c
FROM git.file_changes
WHERE (author = 'Alexey Milovidov') AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY basename(path) AS base
ORDER BY c DESC
LIMIT 10
┌─base───────────────────────────┬───c─┐
│ StorageReplicatedMergeTree.cpp │ 393 │
│ InterpreterSelectQuery.cpp │ 299 │
│ Aggregator.cpp │ 297 │
│ Client.cpp │ 280 │
│ MergeTreeData.cpp │ 274 │
│ Server.cpp │ 264 │
│ ExpressionAnalyzer.cpp │ 259 │
│ StorageMergeTree.cpp │ 239 │
│ Settings.h │ 225 │
│ TCPHandler.cpp │ 205 │
└────────────────────────────────┴─────┘
10 строк в наборе. Время: 0.032 сек. Обработано 266.05 тысяч строк, 5.68 MB (8.22 миллиона строк/с., 175.50 MB/с.)
Это может более точно отразить его области интересов.
Самые большие файлы с наименьшим количеством авторов
Для этого нам сначала нужно определить самые большие файлы. Оценить это, реконструировав полный файл на основе истории коммитов, будет очень дорого!
Для оценки, предположим, что мы ограничены актуальными файлами, мы суммируем добавленные строки и вычитаем удаленные. Затем мы можем вычислить отношение длины к количеству авторов.
play
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
path,
sum(lines_added) - sum(lines_deleted) AS num_lines,
uniqExact(author) AS num_authors,
num_lines / num_authors AS lines_author_ratio
FROM git.file_changes
WHERE path IN (current_files)
GROUP BY path
ORDER BY lines_author_ratio DESC
LIMIT 10
┌─path──────────────────────────────────────────────────────────────────┬─num_lines─┬─num_authors─┬─lines_author_ratio─┐
│ src/Common/ClassificationDictionaries/emotional_dictionary_rus.txt │ 148590 │ 1 │ 148590 │
│ src/Functions/ClassificationDictionaries/emotional_dictionary_rus.txt │ 55533 │ 1 │ 55533 │
│ src/Functions/ClassificationDictionaries/charset_freq.txt │ 35722 │ 1 │ 35722 │
│ src/Common/ClassificationDictionaries/charset_freq.txt │ 35722 │ 1 │ 35722 │
│ tests/integration/test_storage_meilisearch/movies.json │ 19549 │ 1 │ 19549 │
│ tests/queries/0_stateless/02364_multiSearch_function_family.reference │ 12874 │ 1 │ 12874 │
│ src/Functions/ClassificationDictionaries/programming_freq.txt │ 9434 │ 1 │ 9434 │
│ src/Common/ClassificationDictionaries/programming_freq.txt │ 9434 │ 1 │ 9434 │
│ tests/performance/explain_ast.xml │ 5911 │ 1 │ 5911 │
│ src/Analyzer/QueryAnalysisPass.cpp │ 5686 │ 1 │ 5686 │
└───────────────────────────────────────────────────────────────────────┴───────────┴─────────────┴────────────────────┘
10 строк в наборе. Время: 0.138 сек. Обработано 798.15 тысяч строк, 16.57 MB (5.79 миллионов строк/с., 120.11 MB/с.)
Словарные файлы, возможно, не являются реалистичными, поэтому давайте ограничимся только кодом с помощью фильтра по расширению файла!
play
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
path,
sum(lines_added) - sum(lines_deleted) AS num_lines,
uniqExact(author) AS num_authors,
num_lines / num_authors AS lines_author_ratio
FROM git.file_changes
WHERE (path IN (current_files)) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY path
ORDER BY lines_author_ratio DESC
LIMIT 10
┌─path──────────────────────────────────┬─num_lines─┬─num_authors─┬─lines_author_ratio─┐
│ src/Analyzer/QueryAnalysisPass.cpp │ 5686 │ 1 │ 5686 │
│ src/Analyzer/QueryTreeBuilder.cpp │ 880 │ 1 │ 880 │
│ src/Planner/Planner.cpp │ 873 │ 1 │ 873 │
│ src/Backups/RestorerFromBackup.cpp │ 869 │ 1 │ 869 │
│ utils/memcpy-bench/FastMemcpy.h │ 770 │ 1 │ 770 │
│ src/Planner/PlannerActionsVisitor.cpp │ 765 │ 1 │ 765 │
│ src/Functions/sphinxstemen.cpp │ 728 │ 1 │ 728 │
│ src/Planner/PlannerJoinTree.cpp │ 708 │ 1 │ 708 │
│ src/Planner/PlannerJoins.cpp │ 695 │ 1 │ 695 │
│ src/Analyzer/QueryNode.h │ 607 │ 1 │ 607 │
└───────────────────────────────────────┴───────────┴─────────────┴────────────────────┘
10 строк в наборе. Время: 0.140 сек. Обработано 798.15 тысяч строк, 16.84 MB (5.70 миллионов строк/с., 120.32 MB/с.)
В этом есть некоторый предвзятость к современности - новые файлы имеют меньше возможностей для коммитов. Что насчет ограничения файлов как минимум год назад?
play
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
min(time) AS min_date,
path,
sum(lines_added) - sum(lines_deleted) AS num_lines,
uniqExact(author) AS num_authors,
num_lines / num_authors AS lines_author_ratio
FROM git.file_changes
WHERE (path IN (current_files)) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY path
HAVING min_date <= (now() - toIntervalYear(1))
ORDER BY lines_author_ratio DESC
LIMIT 10
┌────────────min_date─┬─path───────────────────────────────────────────────────────────┬─num_lines─┬─num_authors─┬─lines_author_ratio─┐
│ 2021-03-08 07:00:54 │ utils/memcpy-bench/FastMemcpy.h │ 770 │ 1 │ 770 │
│ 2021-05-04 13:47:34 │ src/Functions/sphinxstemen.cpp │ 728 │ 1 │ 728 │
│ 2021-03-14 16:52:51 │ utils/memcpy-bench/glibc/dwarf2.h │ 592 │ 1 │ 592 │
│ 2021-03-08 09:04:52 │ utils/memcpy-bench/FastMemcpy_Avx.h │ 496 │ 1 │ 496 │
│ 2020-10-19 01:10:50 │ tests/queries/0_stateless/01518_nullable_aggregate_states2.sql │ 411 │ 1 │ 411 │
│ 2020-11-24 14:53:34 │ programs/server/GRPCHandler.cpp │ 399 │ 1 │ 399 │
│ 2021-03-09 14:10:28 │ src/DataTypes/Serializations/SerializationSparse.cpp │ 363 │ 1 │ 363 │
│ 2021-08-20 15:06:57 │ src/Functions/vectorFunctions.cpp │ 1327 │ 4 │ 331.75 │
│ 2020-08-04 03:26:23 │ src/Interpreters/MySQL/CreateQueryConvertVisitor.cpp │ 311 │ 1 │ 311 │
│ 2020-11-06 15:45:13 │ src/Storages/Rocksdb/StorageEmbeddedRocksdb.cpp │ 611 │ 2 │ 305.5 │
└─────────────────────┴────────────────────────────────────────────────────────────────┴───────────┴─────────────┴────────────────────┘
10 строк в наборе. Время: 0.143 сек. Обработано 798.15 тысяч строк, 18.00 MB (5.58 миллионов строк/с., 125.87 MB/с.)
Распределение коммитов и строк кода по времени; по дням недели, авторам; для конкретных подкаталогов
Мы интерпретируем это как количество добавленных и удалённых строк по дням недели. В данном случае мы фокусируемся на директории Functions.
play
SELECT
dayOfWeek,
uniq(commit_hash) AS commits,
sum(lines_added) AS lines_added,
sum(lines_deleted) AS lines_deleted
FROM git.file_changes
WHERE path LIKE 'src/Functions%'
GROUP BY toDayOfWeek(time) AS dayOfWeek
┌─dayOfWeek─┬─commits─┬─lines_added─┬─lines_deleted─┐
│ 1 │ 476 │ 24619 │ 15782 │
│ 2 │ 434 │ 18098 │ 9938 │
│ 3 │ 496 │ 26562 │ 20883 │
│ 4 │ 587 │ 65674 │ 18862 │
│ 5 │ 504 │ 85917 │ 14518 │
│ 6 │ 314 │ 13604 │ 10144 │
│ 7 │ 294 │ 11938 │ 6451 │
└───────────┴─────────┴─────────────┴───────────────┘
7 строк в наборе. Время: 0.034 сек. Обработано 266.05 тысяч строк, 14.66 MB (7.73 миллиона строк/с., 425.56 MB/с.)
И по времени суток,
play
SELECT
hourOfDay,
uniq(commit_hash) AS commits,
sum(lines_added) AS lines_added,
sum(lines_deleted) AS lines_deleted
FROM git.file_changes
WHERE path LIKE 'src/Functions%'
GROUP BY toHour(time) AS hourOfDay
┌─hourOfDay─┬─commits─┬─lines_added─┬─lines_deleted─┐
│ 0 │ 71 │ 4169 │ 3404 │
│ 1 │ 90 │ 2174 │ 1927 │
│ 2 │ 65 │ 2343 │ 1515 │
│ 3 │ 76 │ 2552 │ 493 │
│ 4 │ 62 │ 1480 │ 1304 │
│ 5 │ 38 │ 1644 │ 253 │
│ 6 │ 104 │ 4434 │ 2979 │
│ 7 │ 117 │ 4171 │ 1678 │
│ 8 │ 106 │ 4604 │ 4673 │
│ 9 │ 135 │ 60550 │ 2678 │
│ 10 │ 149 │ 6133 │ 3482 │
│ 11 │ 182 │ 8040 │ 3833 │
│ 12 │ 209 │ 29428 │ 15040 │
│ 13 │ 187 │ 10204 │ 5491 │
│ 14 │ 204 │ 9028 │ 6060 │
│ 15 │ 231 │ 15179 │ 10077 │
│ 16 │ 196 │ 9568 │ 5925 │
│ 17 │ 138 │ 4941 │ 3849 │
│ 18 │ 123 │ 4193 │ 3036 │
│ 19 │ 165 │ 8817 │ 6646 │
│ 20 │ 140 │ 3749 │ 2379 │
│ 21 │ 132 │ 41585 │ 4182 │
│ 22 │ 85 │ 4094 │ 3955 │
│ 23 │ 100 │ 3332 │ 1719 │
└───────────┴─────────┴─────────────┴───────────────┘
24 строки в наборе. Время: 0.039 сек. Обработано 266.05 тысяч строк, 14.66 MB (6.77 миллиона строк/с., 372.89 MB/с.)
Это распределение имеет смысл, учитывая, что большая часть нашей команды разработчиков находится в Амстердаме. Функции bar помогают нам визуализировать эти распределения:
play
SELECT
hourOfDay,
bar(commits, 0, 400, 50) AS commits,
bar(lines_added, 0, 30000, 50) AS lines_added,
bar(lines_deleted, 0, 15000, 50) AS lines_deleted
FROM
(
SELECT
hourOfDay,
uniq(commit_hash) AS commits,
sum(lines_added) AS lines_added,
sum(lines_deleted) AS lines_deleted
FROM git.file_changes
WHERE path LIKE 'src/Functions%'
GROUP BY toHour(time) AS hourOfDay
)
┌─hourOfDay─┬─commits───────────────────────┬─lines_added────────────────────────────────────────┬─lines_deleted──────────────────────────────────────┐
│ 0 │ ████████▊ │ ██████▊ │ ███████████▎ │
│ 1 │ ███████████▎ │ ███▌ │ ██████▍ │
│ 2 │ ████████ │ ███▊ │ █████ │
│ 3 │ █████████▌ │ ████▎ │ █▋ │
│ 4 │ ███████▋ │ ██▍ │ ████▎ │
│ 5 │ ████▋ │ ██▋ │ ▋ │
│ 6 │ █████████████ │ ███████▍ │ █████████▊ │
│ 7 │ ██████████████▋ │ ██████▊ │ █████▌ │
│ 8 │ █████████████▎ │ ███████▋ │ ███████████████▌ │
│ 9 │ ████████████████▊ │ ██████████████████████████████████████████████████ │ ████████▊ │
│ 10 │ ██████████████████▋ │ ██████████▏ │ ███████████▌ │
│ 11 │ ██████████████████████▋ │ █████████████▍ │ ████████████▋ │
│ 12 │ ██████████████████████████ │ █████████████████████████████████████████████████ │ ██████████████████████████████████████████████████ │
│ 13 │ ███████████████████████▍ │ █████████████████ │ ██████████████████▎ │
│ 14 │ █████████████████████████▌ │ ███████████████ │ ████████████████████▏ │
│ 15 │ ████████████████████████████▊ │ █████████████████████████▎ │ █████████████████████████████████▌ │
│ 16 │ ████████████████████████▌ │ ███████████████▊ │ ███████████████████▋ │
│ 17 │ █████████████████▎ │ ████████▏ │ ████████████▋ │
│ 18 │ ███████████████▍ │ ██████▊ │ ██████████ │
│ 19 │ ████████████████████▋ │ ██████████████▋ │ ██████████████████████▏ │
│ 20 │ █████████████████▌ │ ██████▏ │ ███████▊ │
│ 21 │ ████████████████▌ │ ██████████████████████████████████████████████████ │ █████████████▊ │
│ 22 │ ██████████▋ │ ██████▋ │ █████████████▏ │
│ 23 │ ████████████▌ │ █████▌ │ █████▋ │
└───────────┴───────────────────────────────┴────────────────────────────────────────────────────┴────────────────────────────────────────────────────┘
24 строки в наборе. Время: 0.038 сек. Обработано 266.05 тысяч строк, 14.66 MB (7.09 миллиона строк/с., 390.69 MB/с.)
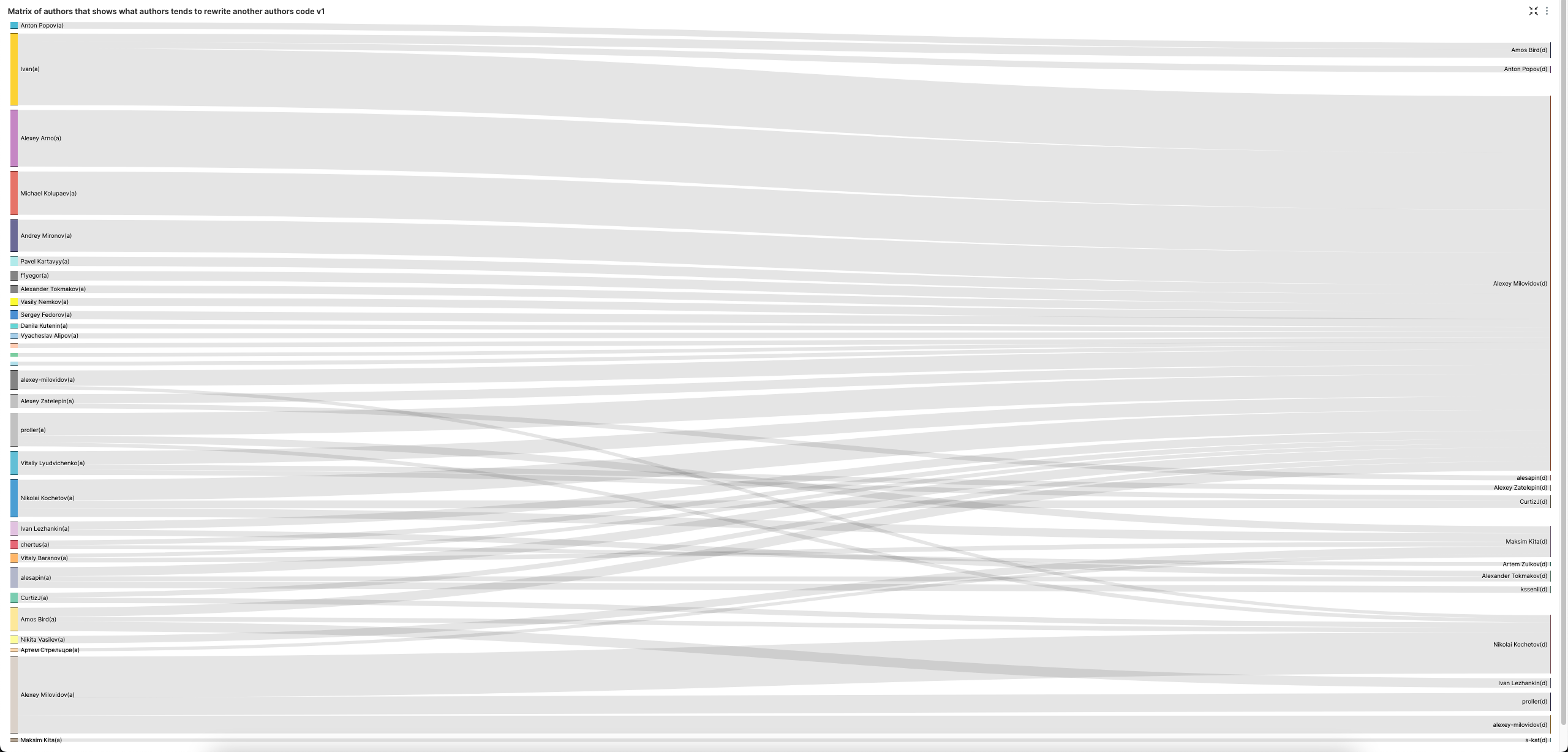
Матрица авторов, показывающая, какие авторы перерабатывают код других авторов
sign = -1 указывает на удаление кода. Мы исключаем пунктуацию и вставку пустых строк.
play
SELECT
prev_author || '(a)' as add_author,
author || '(d)' as delete_author,
count() AS c
FROM git.line_changes
WHERE (sign = -1) AND (file_extension IN ('h', 'cpp')) AND (line_type NOT IN ('Punct', 'Empty')) AND (author != prev_author) AND (prev_author != '')
GROUP BY
prev_author,
author
ORDER BY c DESC
LIMIT 1 BY prev_author
LIMIT 100
┌─prev_author──────────┬─author───────────┬─────c─┐
│ Ivan │ Alexey Milovidov │ 18554 │
│ Alexey Arno │ Alexey Milovidov │ 18475 │
│ Michael Kolupaev │ Alexey Milovidov │ 14135 │
│ Alexey Milovidov │ Nikolai Kochetov │ 13435 │
│ Andrey Mironov │ Alexey Milovidov │ 10418 │
│ proller │ Alexey Milovidov │ 7280 │
│ Nikolai Kochetov │ Alexey Milovidov │ 6806 │
│ alexey-milovidov │ Alexey Milovidov │ 5027 │
│ Vitaliy Lyudvichenko │ Alexey Milovidov │ 4390 │
│ Amos Bird │ Ivan Lezhankin │ 3125 │
│ f1yegor │ Alexey Milovidov │ 3119 │
│ Pavel Kartavyy │ Alexey Milovidov │ 3087 │
│ Alexey Zatelepin │ Alexey Milovidov │ 2978 │
│ alesapin │ Alexey Milovidov │ 2949 │
│ Sergey Fedorov │ Alexey Milovidov │ 2727 │
│ Ivan Lezhankin │ Alexey Milovidov │ 2618 │
│ Vasily Nemkov │ Alexey Milovidov │ 2547 │
│ Alexander Tokmakov │ Alexey Milovidov │ 2493 │
│ Nikita Vasilev │ Maksim Kita │ 2420 │
│ Anton Popov │ Amos Bird │ 2127 │
└──────────────────────┴──────────────────┴───────┘
20 строк в наборе. Время: 0.098 сек. Обработано 7.54 миллиона строк, 42.16 MB (76.67 миллиона строк/с., 428.99 MB/с.)
Санки-диаграмма (SuperSet) позволяет красиво визуализировать это. Обратите внимание, что мы увеличили наш LIMIT BY до 3, чтобы получить 3 главных удалителей кода для каждого автора, улучшая разнообразие в визуализации.
Алексей явно любит удалять код других людей. Исключим его для более сбалансированного взгляда на удаление кода.
Кто является автором с наибольшим процентом вкладов по дням недели?
Если рассматривать только по количеству коммитов:
play
SELECT
day_of_week,
author,
count() AS c
FROM git.commits
GROUP BY
dayOfWeek(time) AS day_of_week,
author
ORDER BY
day_of_week ASC,
c DESC
LIMIT 1 BY day_of_week
┌─day_of_week─┬─author───────────┬────c─┐
│ 1 │ Alexey Milovidov │ 2204 │
│ 2 │ Alexey Milovidov │ 1588 │
│ 3 │ Alexey Milovidov │ 1725 │
│ 4 │ Alexey Milovidov │ 1915 │
│ 5 │ Alexey Milovidov │ 1940 │
│ 6 │ Alexey Milovidov │ 1851 │
│ 7 │ Alexey Milovidov │ 2400 │
└─────────────┴──────────────────┴──────┘
7 строк в наборе. Время: 0.012 сек. Обработано 62.78 тысячи строк, 395.47 KB (5.44 миллиона строк/с., 34.27 MB/с.)
Хорошо, здесь есть некоторые возможные преимущества у самого продолжительного автора - нашего основателя Алексея. Ограничим наш анализ последним годом.
play
SELECT
day_of_week,
author,
count() AS c
FROM git.commits
WHERE time > (now() - toIntervalYear(1))
GROUP BY
dayOfWeek(time) AS day_of_week,
author
ORDER BY
day_of_week ASC,
c DESC
LIMIT 1 BY day_of_week
┌─day_of_week─┬─author───────────┬───c─┐
│ 1 │ Alexey Milovidov │ 198 │
│ 2 │ alesapin │ 162 │
│ 3 │ alesapin │ 163 │
│ 4 │ Azat Khuzhin │ 166 │
│ 5 │ alesapin │ 191 │
│ 6 │ Alexey Milovidov │ 179 │
│ 7 │ Alexey Milovidov │ 243 │
└─────────────┴──────────────────┴─────┘
7 строк в наборе. Время: 0.004 сек. Обработано 21.82 тысячи строк, 140.02 KB (4.88 миллиона строк/с., 31.29 MB/с.)
Это все еще немного просто и не отражает работу людей.
Лучшей метрикой может быть, кто является ведущим автором каждый день в процентном отношении от общего объема выполненной работы за последний год. Обратите внимание, что мы рассматриваем удаление и добавление кода одинаково.
play
SELECT
top_author.day_of_week,
top_author.author,
top_author.author_work / all_work.total_work AS top_author_percent
FROM
(
SELECT
day_of_week,
author,
sum(lines_added) + sum(lines_deleted) AS author_work
FROM git.file_changes
WHERE time > (now() - toIntervalYear(1))
GROUP BY
author,
dayOfWeek(time) AS day_of_week
ORDER BY
day_of_week ASC,
author_work DESC
LIMIT 1 BY day_of_week
) AS top_author
INNER JOIN
(
SELECT
day_of_week,
sum(lines_added) + sum(lines_deleted) AS total_work
FROM git.file_changes
WHERE time > (now() - toIntervalYear(1))
GROUP BY dayOfWeek(time) AS day_of_week
) AS all_work USING (day_of_week)
┌─day_of_week─┬─author──────────────┬──top_author_percent─┐
│ 1 │ Alexey Milovidov │ 0.3168282877768332 │
│ 2 │ Mikhail f. Shiryaev │ 0.3523434231193969 │
│ 3 │ vdimir │ 0.11859742484577324 │
│ 4 │ Nikolay Degterinsky │ 0.34577318920318467 │
│ 5 │ Alexey Milovidov │ 0.13208704423684223 │
│ 6 │ Alexey Milovidov │ 0.18895257783624633 │
│ 7 │ Robert Schulze │ 0.3617405888930302 │
└─────────────┴─────────────────────┴─────────────────────┘
7 строк в наборе. Время: 0.014 сек. Обработано 106.12 тысяч строк, 1.38 MB (7.61 миллиона строк/с., 98.65 MB/с.)
Распределение возраста кода по репозиторию
Мы ограничиваем анализ текущими файлами. Для краткости мы ограничиваем результаты глубиной 2 и 5 файлов на корневую папку. Настройте по мере необходимости.
play
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
concat(root, '/', sub_folder) AS folder,
round(avg(days_present)) AS avg_age_of_files,
min(days_present) AS min_age_files,
max(days_present) AS max_age_files,
count() AS c
FROM
(
SELECT
path,
dateDiff('day', min(time), toDate('2022-11-03')) AS days_present
FROM git.file_changes
WHERE (path IN (current_files)) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY path
)
GROUP BY
splitByChar('/', path)[1] AS root,
splitByChar('/', path)[2] AS sub_folder
ORDER BY
root ASC,
c DESC
LIMIT 5 BY root
┌─folder───────────────────────────┬─avg_age_of_files─┬─min_age_files─┬─max_age_files─┬────c─┐
│ base/base │ 387 │ 201 │ 397 │ 84 │
│ base/glibc-compatibility │ 887 │ 59 │ 993 │ 19 │
│ base/consistent-hashing │ 993 │ 993 │ 993 │ 5 │
│ base/widechar_width │ 993 │ 993 │ 993 │ 2 │
│ base/consistent-hashing-sumbur │ 993 │ 993 │ 993 │ 2 │
│ docker/test │ 1043 │ 1043 │ 1043 │ 1 │
│ programs/odbc-bridge │ 835 │ 91 │ 945 │ 25 │
│ programs/copier │ 587 │ 14 │ 945 │ 22 │
│ programs/library-bridge │ 155 │ 47 │ 608 │ 21 │
│ programs/disks │ 144 │ 62 │ 150 │ 14 │
│ programs/server │ 874 │ 709 │ 945 │ 10 │
│ rust/BLAKE3 │ 52 │ 52 │ 52 │ 1 │
│ src/Functions │ 752 │ 0 │ 944 │ 809 │
│ src/Storages │ 700 │ 8 │ 944 │ 736 │
│ src/Interpreters │ 684 │ 3 │ 944 │ 490 │
│ src/Processors │ 703 │ 44 │ 944 │ 482 │
│ src/Common │ 673 │ 7 │ 944 │ 473 │
│ tests/queries │ 674 │ -5 │ 945 │ 3777 │
│ tests/integration │ 656 │ 132 │ 945 │ 4 │
│ utils/memcpy-bench │ 601 │ 599 │ 605 │ 10 │
│ utils/keeper-bench │ 570 │ 569 │ 570 │ 7 │
│ utils/durability-test │ 793 │ 793 │ 793 │ 4 │
│ utils/self-extracting-executable │ 143 │ 143 │ 143 │ 3 │
│ utils/self-extr-exec │ 224 │ 224 │ 224 │ 2 │
└──────────────────────────────────┴──────────────────┴───────────────┴───────────────┴──────┘
24 строки в наборе. Время: 0.129 сек. Обработано 798.15 тысяч строк, 15.11 MB (6.19 миллионов строк/с., 117.08 MB/с.)
Какой процент кода для автора был удалён другими авторами?
Для этого вопроса нам нужно количество строк, написанных автором, делённое на общее количество строк, которые были удалены другим участником.
play
SELECT
k,
written_code.c,
removed_code.c,
removed_code.c / written_code.c AS remove_ratio
FROM
(
SELECT
author AS k,
count() AS c
FROM git.line_changes
WHERE (sign = 1) AND (file_extension IN ('h', 'cpp')) AND (line_type NOT IN ('Punct', 'Empty'))
GROUP BY k
) AS written_code
INNER JOIN
(
SELECT
prev_author AS k,
count() AS c
FROM git.line_changes
WHERE (sign = -1) AND (file_extension IN ('h', 'cpp')) AND (line_type NOT IN ('Punct', 'Empty')) AND (author != prev_author)
GROUP BY k
) AS removed_code USING (k)
WHERE written_code.c > 1000
ORDER BY remove_ratio DESC
LIMIT 10
┌─k──────────────────┬─────c─┬─removed_code.c─┬───────remove_ratio─┐
│ Marek Vavruša │ 1458 │ 1318 │ 0.9039780521262003 │
│ Ivan │ 32715 │ 27500 │ 0.8405930001528351 │
│ artpaul │ 3450 │ 2840 │ 0.8231884057971014 │
│ Silviu Caragea │ 1542 │ 1209 │ 0.7840466926070039 │
│ Ruslan │ 1027 │ 802 │ 0.7809152872444012 │
│ Tsarkova Anastasia │ 1755 │ 1364 │ 0.7772079772079772 │
│ Vyacheslav Alipov │ 3526 │ 2727 │ 0.7733976176971072 │
│ Marek Vavruša │ 1467 │ 1124 │ 0.7661895023858214 │
│ f1yegor │ 7194 │ 5213 │ 0.7246316374756742 │
│ kreuzerkrieg │ 3406 │ 2468 │ 0.724603640634175 │
└────────────────────┴───────┴────────────────┴────────────────────┘
10 строк в наборе. Время: 0.126 сек. Обработано 15.07 миллионов строк, 73.51 MB (119.97 миллионов строк/с., 585.16 MB/с.)
Список файлов, которые были переписаны наибольшее количество раз
Самый простой подход к этому вопросу заключается в том, чтобы просто посчитать наибольшее количество изменений строк по пути (с ограничением на текущие файлы), например:
WITH current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
)
SELECT
path,
count() AS c
FROM git.line_changes
WHERE (file_extension IN ('h', 'cpp', 'sql')) AND (path IN (current_files))
GROUP BY path
ORDER BY c DESC
LIMIT 10
┌─path───────────────────────────────────────────────────┬─────c─┐
│ src/Storages/StorageReplicatedMergeTree.cpp │ 21871 │
│ src/Storages/MergeTree/MergeTreeData.cpp │ 17709 │
│ programs/client/Client.cpp │ 15882 │
│ src/Storages/MergeTree/MergeTreeDataSelectExecutor.cpp │ 14249 │
│ src/Interpreters/InterpreterSelectQuery.cpp │ 12636 │
│ src/Parsers/ExpressionListParsers.cpp │ 11794 │
│ src/Analyzer/QueryAnalysisPass.cpp │ 11760 │
│ src/Coordination/KeeperStorage.cpp │ 10225 │
│ src/Functions/FunctionsConversion.h │ 9247 │
│ src/Parsers/ExpressionElementParsers.cpp │ 8197 │
└────────────────────────────────────────────────────────┴───────┘
10 строк в наборе. Время: 0.160 сек. Обработано 8.07 миллионов строк, 98.99 MB (50.49 миллионов строк/с., 619.49 MB/с.)
Это не учитывает понятие "переписывания", когда большая часть файла изменяется в любом коммите. Это требует более сложного запроса. Если мы считаем переписыванием, когда более 50% файла удаляется и 50% добавляется. Вы можете настроить запрос в соответствии с вашим собственным пониманием того, что составляет это.
Запрос ограничен только текущими файлами. Мы перечисляем все изменения файла, группируя по path и commit_hash, возвращая количество добавленных и удалённых строк. Используя оконную функцию, мы оцениваем общий размер файла в любой момент времени, выполняя накопительную сумму и оценивая влияние любого изменения на размер файла как lines added - lines removed. Используя эту статистику, мы можем подсчитать процент файла, который был добавлен или удалён для каждого изменения. Наконец, мы считаем количество изменений файла, которые составляют переписывание, т.е. (percent_add >= 0.5) AND (percent_delete >= 0.5) AND current_size > 50. Обратите внимание, что мы требуем, чтобы файлы содержали более 50 строк, чтобы избежать считывания ранних взносов в файл, которые могут быть засчитаны в качестве переписывания. Это также избегает предвзятости к очень маленьким файлам, которые могут быть более склонны к переписыванию.
play
WITH
current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
),
changes AS
(
SELECT
path,
max(time) AS max_time,
commit_hash,
any(lines_added) AS num_added,
any(lines_deleted) AS num_deleted,
any(change_type) AS type
FROM git.file_changes
WHERE (change_type IN ('Add', 'Modify')) AND (path IN (current_files)) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY
path,
commit_hash
ORDER BY
path ASC,
max_time ASC
),
rewrites AS
(
SELECT
path,
commit_hash,
max_time,
type,
num_added,
num_deleted,
sum(num_added - num_deleted) OVER (PARTITION BY path ORDER BY max_time ASC) AS current_size,
if(current_size > 0, num_added / current_size, 0) AS percent_add,
if(current_size > 0, num_deleted / current_size, 0) AS percent_delete
FROM changes
)
SELECT
path,
count() AS num_rewrites
FROM rewrites
WHERE (type = 'Modify') AND (percent_add >= 0.5) AND (percent_delete >= 0.5) AND (current_size > 50)
GROUP BY path
ORDER BY num_rewrites DESC
LIMIT 10
┌─path──────────────────────────────────────────────────┬─num_rewrites─┐
│ src/Storages/WindowView/StorageWindowView.cpp │ 8 │
│ src/Functions/array/arrayIndex.h │ 7 │
│ src/Dictionaries/CacheDictionary.cpp │ 6 │
│ src/Dictionaries/RangeHashedDictionary.cpp │ 5 │
│ programs/client/Client.cpp │ 4 │
│ src/Functions/polygonPerimeter.cpp │ 4 │
│ src/Functions/polygonsEquals.cpp │ 4 │
│ src/Functions/polygonsWithin.cpp │ 4 │
│ src/Processors/Formats/Impl/ArrowColumnToCHColumn.cpp │ 4 │
│ src/Functions/polygonsSymDifference.cpp │ 4 │
└───────────────────────────────────────────────────────┴──────────────┘
10 строк в наборе. Время: 0.299 сек. Обработано 798.15 тысяч строк, 31.52 MB (2.67 миллиона строк/с., 105.29 MB/с.)
Какой день недели имеет наибольшие шансы остаться в репозитории?
Для этого мы должны идентифицировать строку кода уникально. Мы оцениваем это (поскольку одна и та же строка может несколько раз появляться в файле) по пути и содержимому строки.
Мы запрашиваем добавленные строки, присоединяя их к удалённым строкам - фильтруя случаи, когда последние происходят более недавно, чем первые. Это даёт нам удалённые строки, из которых мы можем вычислить время между этими двумя событиями.
Наконец, мы агрегируем по этому набору данных, чтобы вычислить среднее количество дней, которые строки остаются в репозитории по дням недели.
play
SELECT
day_of_week_added,
count() AS num,
avg(days_present) AS avg_days_present
FROM
(
SELECT
added_code.line,
added_code.time AS added_day,
dateDiff('day', added_code.time, removed_code.time) AS days_present
FROM
(
SELECT
path,
line,
max(time) AS time
FROM git.line_changes
WHERE (sign = 1) AND (line_type NOT IN ('Punct', 'Empty'))
GROUP BY
path,
line
) AS added_code
INNER JOIN
(
SELECT
path,
line,
max(time) AS time
FROM git.line_changes
WHERE (sign = -1) AND (line_type NOT IN ('Punct', 'Empty'))
GROUP BY
path,
line
) AS removed_code USING (path, line)
WHERE removed_code.time > added_code.time
)
GROUP BY dayOfWeek(added_day) AS day_of_week_added
┌─day_of_week_added─┬────num─┬───avg_days_present─┐
│ 1 │ 171879 │ 193.81759260875384 │
│ 2 │ 141448 │ 153.0931013517335 │
│ 3 │ 161230 │ 137.61553681076722 │
│ 4 │ 255728 │ 121.14149799787273 │
│ 5 │ 203907 │ 141.60181847606998 │
│ 6 │ 62305 │ 202.43449161383518 │
│ 7 │ 70904 │ 220.0266134491707 │
└───────────────────┴────────┴────────────────────┘
7 строк в наборе. Время: 3.965 сек. Обработано 15.07 миллионов строк, 1.92 GB (3.80 миллиона строк/с., 483.50 MB/с.)
title: 'Файлы, отсортированные по среднему возрасти кода'
sidebar_label: 'Файлы, отсортированные по среднему возрасти кода'
keywords: ['файлы', 'средний возраст кода', 'коды']
description: 'Запрос, использующий принцип уникальной идентификации строк кода по пути и содержимому.'
Файлы отсортированные по среднему возрасти кода
Этот запрос использует тот же принцип, что и В какой день недели код имеет наибольшую вероятность остаться в репозитории - с целью уникально идентифицировать строку кода, используя путь и содержимое строки. Это позволяет нам определить время между добавлением и удалением строки. Мы фильтруем только текущие файлы и коды и усредняем время для каждого файла по строкам.
play
WITH
current_files AS
(
SELECT path
FROM
(
SELECT
old_path AS path,
max(time) AS last_time,
2 AS change_type
FROM git.file_changes
GROUP BY old_path
UNION ALL
SELECT
path,
max(time) AS last_time,
argMax(change_type, time) AS change_type
FROM git.clickhouse_file_changes
GROUP BY path
)
GROUP BY path
HAVING (argMax(change_type, last_time) != 2) AND (NOT match(path, '(^dbms/)|(^libs/)|(^tests/testflows/)|(^programs/server/store/)'))
ORDER BY path ASC
),
lines_removed AS
(
SELECT
added_code.path AS path,
added_code.line,
added_code.time AS added_day,
dateDiff('day', added_code.time, removed_code.time) AS days_present
FROM
(
SELECT
path,
line,
max(time) AS time,
any(file_extension) AS file_extension
FROM git.line_changes
WHERE (sign = 1) AND (line_type NOT IN ('Punct', 'Empty'))
GROUP BY
path,
line
) AS added_code
INNER JOIN
(
SELECT
path,
line,
max(time) AS time
FROM git.line_changes
WHERE (sign = -1) AND (line_type NOT IN ('Punct', 'Empty'))
GROUP BY
path,
line
) AS removed_code USING (path, line)
WHERE (removed_code.time > added_code.time) AND (path IN (current_files)) AND (file_extension IN ('h', 'cpp', 'sql'))
)
SELECT
path,
avg(days_present) AS avg_code_age
FROM lines_removed
GROUP BY path
ORDER BY avg_code_age DESC
LIMIT 10
┌─path────────────────────────────────────────────────────────────┬──────avg_code_age─┐
│ utils/corrector_utf8/corrector_utf8.cpp │ 1353.888888888889 │
│ tests/queries/0_stateless/01288_shard_max_network_bandwidth.sql │ 881 │
│ src/Functions/replaceRegexpOne.cpp │ 861 │
│ src/Functions/replaceRegexpAll.cpp │ 861 │
│ src/Functions/replaceOne.cpp │ 861 │
│ utils/zookeeper-remove-by-list/main.cpp │ 838.25 │
│ tests/queries/0_stateless/01356_state_resample.sql │ 819 │
│ tests/queries/0_stateless/01293_create_role.sql │ 819 │
│ src/Functions/ReplaceStringImpl.h │ 810 │
│ src/Interpreters/createBlockSelector.cpp │ 795 │
└─────────────────────────────────────────────────────────────────┴───────────────────┘
10 rows in set. Elapsed: 3.134 sec. Processed 16.13 million rows, 1.83 GB (5.15 million rows/s., 582.99 MB/s.)
Существует несколько способов решить этот вопрос. Сосредоточившись на соотношении кода к тестам, этот запрос относительно прост - посчитаем количество вкладов в папки, содержащие tests, и вычислим соотношение к общему количеству вкладов.
Обратите внимание, что мы ограничиваем пользователей более чем 20 изменениями, чтобы сосредоточиться на регулярных участниках и избежать предвзятости к разовым вкладам.
play
SELECT
author,
countIf((file_extension IN ('h', 'cpp', 'sql', 'sh', 'py', 'expect')) AND (path LIKE '%tests%')) AS test,
countIf((file_extension IN ('h', 'cpp', 'sql')) AND (NOT (path LIKE '%tests%'))) AS code,
code / (code + test) AS ratio_code
FROM git.clickhouse_file_changes
GROUP BY author
HAVING code > 20
ORDER BY code DESC
LIMIT 20
┌─author───────────────┬─test─┬──code─┬─────────ratio_code─┐
│ Alexey Milovidov │ 6617 │ 41799 │ 0.8633303040317251 │
│ Nikolai Kochetov │ 916 │ 13361 │ 0.9358408629263851 │
│ alesapin │ 2408 │ 8796 │ 0.785076758300607 │
│ kssenii │ 869 │ 6769 │ 0.8862267609321812 │
│ Maksim Kita │ 799 │ 5862 │ 0.8800480408347096 │
│ Alexander Tokmakov │ 1472 │ 5727 │ 0.7955271565495208 │
│ Vitaly Baranov │ 1764 │ 5521 │ 0.7578586135895676 │
│ Ivan Lezhankin │ 843 │ 4698 │ 0.8478613968597726 │
│ Anton Popov │ 599 │ 4346 │ 0.8788675429726996 │
│ Ivan │ 2630 │ 4269 │ 0.6187853312074214 │
│ Azat Khuzhin │ 1664 │ 3697 │ 0.689610147360567 │
│ Amos Bird │ 400 │ 2901 │ 0.8788245986064829 │
│ proller │ 1207 │ 2377 │ 0.6632254464285714 │
│ chertus │ 453 │ 2359 │ 0.8389046941678521 │
│ alexey-milovidov │ 303 │ 2321 │ 0.8845274390243902 │
│ Alexey Arno │ 169 │ 2310 │ 0.9318273497377975 │
│ Vitaliy Lyudvichenko │ 334 │ 2283 │ 0.8723729461215132 │
│ Robert Schulze │ 182 │ 2196 │ 0.9234650967199327 │
│ CurtizJ │ 460 │ 2158 │ 0.8242933537051184 │
│ Alexander Kuzmenkov │ 298 │ 2092 │ 0.8753138075313808 │
└──────────────────────┴──────┴───────┴────────────────────┘
20 rows in set. Elapsed: 0.034 sec. Processed 266.05 thousand rows, 4.65 MB (7.93 million rows/s., 138.76 MB/s.)
Мы можем изобразить это распределение в виде гистограммы.
play
WITH (
SELECT histogram(10)(ratio_code) AS hist
FROM
(
SELECT
author,
countIf((file_extension IN ('h', 'cpp', 'sql', 'sh', 'py', 'expect')) AND (path LIKE '%tests%')) AS test,
countIf((file_extension IN ('h', 'cpp', 'sql')) AND (NOT (path LIKE '%tests%'))) AS code,
code / (code + test) AS ratio_code
FROM git.clickhouse_file_changes
GROUP BY author
HAVING code > 20
ORDER BY code DESC
LIMIT 20
)
) AS hist
SELECT
arrayJoin(hist).1 AS lower,
arrayJoin(hist).2 AS upper,
bar(arrayJoin(hist).3, 0, 100, 500) AS bar
┌──────────────lower─┬──────────────upper─┬─bar───────────────────────────┐
│ 0.6187853312074214 │ 0.6410053888179964 │ █████ │
│ 0.6410053888179964 │ 0.6764177968945693 │ █████ │
│ 0.6764177968945693 │ 0.7237343804750673 │ █████ │
│ 0.7237343804750673 │ 0.7740802855073157 │ █████▋ │
│ 0.7740802855073157 │ 0.807297655565091 │ ████████▋ │
│ 0.807297655565091 │ 0.8338381996094653 │ ██████▎ │
│ 0.8338381996094653 │ 0.8533566747727687 │ ████████▋ │
│ 0.8533566747727687 │ 0.871392376017531 │ █████████▍ │
│ 0.871392376017531 │ 0.904916108899021 │ ████████████████████████████▋ │
│ 0.904916108899021 │ 0.9358408629263851 │ █████████████████▌ │
└────────────────────┴────────────────────┴───────────────────────────────┘
10 rows in set. Elapsed: 0.051 sec. Processed 266.05 thousand rows, 4.65 MB (5.24 million rows/s., 91.64 MB/s.)
Большинство участников пишут больше кода, чем тестов, как и следовало ожидать.
Что насчет тех, кто добавляет больше всего комментариев при внесении кода?
play
SELECT
author,
avg(ratio_comments) AS avg_ratio_comments,
sum(code) AS code
FROM
(
SELECT
author,
commit_hash,
countIf(line_type = 'Comment') AS comments,
countIf(line_type = 'Code') AS code,
if(comments > 0, comments / (comments + code), 0) AS ratio_comments
FROM git.clickhouse_line_changes
GROUP BY
author,
commit_hash
)
GROUP BY author
ORDER BY code DESC
LIMIT 10
┌─author─────────────┬──avg_ratio_comments─┬────code─┐
│ Alexey Milovidov │ 0.1034915408309902 │ 1147196 │
│ s-kat │ 0.1361718900215362 │ 614224 │
│ Nikolai Kochetov │ 0.08722993407690126 │ 218328 │
│ alesapin │ 0.1040477684726504 │ 198082 │
│ Vitaly Baranov │ 0.06446875712939285 │ 161801 │
│ Maksim Kita │ 0.06863376297549255 │ 156381 │
│ Alexey Arno │ 0.11252677608033655 │ 146642 │
│ Vitaliy Zakaznikov │ 0.06199215397180561 │ 138530 │
│ kssenii │ 0.07455322590796751 │ 131143 │
│ Artur │ 0.12383737231074826 │ 121484 │
└────────────────────┴─────────────────────┴─────────┘
10 rows in set. Elapsed: 0.290 sec. Processed 7.54 million rows, 394.57 MB (26.00 million rows/s., 1.36 GB/s.)
Обратите внимание, что мы сортируем по вкладкам кода. Удивительно высокий % для всех наших крупнейших участников и часть того, что делает наш код таким читаемым.
Чтобы вычислить это по авторам, ничего сложного,
SELECT
author,
countIf(line_type = 'Code') AS code_lines,
countIf((line_type = 'Comment') OR (line_type = 'Punct')) AS comments,
code_lines / (comments + code_lines) AS ratio_code,
toStartOfWeek(time) AS week
FROM git.line_changes
GROUP BY
time,
author
ORDER BY
author ASC,
time ASC
LIMIT 10
┌─author──────────────────────┬─code_lines─┬─comments─┬─────────ratio_code─┬───────week─┐
│ 1lann │ 8 │ 0 │ 1 │ 2022-03-06 │
│ 20018712 │ 2 │ 0 │ 1 │ 2020-09-13 │
│ 243f6a8885a308d313198a2e037 │ 0 │ 2 │ 0 │ 2020-12-06 │
│ 243f6a8885a308d313198a2e037 │ 0 │ 112 │ 0 │ 2020-12-06 │
│ 243f6a8885a308d313198a2e037 │ 0 │ 14 │ 0 │ 2020-12-06 │
│ 3ldar-nasyrov │ 2 │ 0 │ 1 │ 2021-03-14 │
│ 821008736@qq.com │ 27 │ 2 │ 0.9310344827586207 │ 2019-04-21 │
│ ANDREI STAROVEROV │ 182 │ 60 │ 0.7520661157024794 │ 2021-05-09 │
│ ANDREI STAROVEROV │ 7 │ 0 │ 1 │ 2021-05-09 │
│ ANDREI STAROVEROV │ 32 │ 12 │ 0.7272727272727273 │ 2021-05-09 │
└─────────────────────────────┴────────────┴──────────┴────────────────────┴────────────┘
10 rows in set. Elapsed: 0.145 sec. Processed 7.54 million rows, 51.09 MB (51.83 million rows/s., 351.44 MB/s.)
В идеале, однако, мы хотим увидеть, как это меняется в совокупности по всем авторам с первого дня, когда они начинают коммитить. Снижают ли они постепенно количество комментариев, которые пишут?
Чтобы вычислить это, мы вначале определяем отношение комментариев каждого автора с течением времени - аналогично Кто чаще всего пишет больше тестов / CPP кода / комментариев?. Это соединяется с датой начала каждого автора, позволяя нам вычислить соотношение комментариев по смещению недели.
После вычисления среднего по смещению недель по всем авторам, мы отбираем эти результаты, выбирая каждую 10-ю неделю.
play
WITH author_ratios_by_offset AS
(
SELECT
author,
dateDiff('week', start_dates.start_date, contributions.week) AS week_offset,
ratio_code
FROM
(
SELECT
author,
toStartOfWeek(min(time)) AS start_date
FROM git.line_changes
WHERE file_extension IN ('h', 'cpp', 'sql')
GROUP BY author AS start_dates
) AS start_dates
INNER JOIN
(
SELECT
author,
countIf(line_type = 'Code') AS code,
countIf((line_type = 'Comment') OR (line_type = 'Punct')) AS comments,
comments / (comments + code) AS ratio_code,
toStartOfWeek(time) AS week
FROM git.line_changes
WHERE (file_extension IN ('h', 'cpp', 'sql')) AND (sign = 1)
GROUP BY
time,
author
HAVING code > 20
ORDER BY
author ASC,
time ASC
) AS contributions USING (author)
)
SELECT
week_offset,
avg(ratio_code) AS avg_code_ratio
FROM author_ratios_by_offset
GROUP BY week_offset
HAVING (week_offset % 10) = 0
ORDER BY week_offset ASC
LIMIT 20
┌─week_offset─┬──────avg_code_ratio─┐
│ 0 │ 0.21626798253005078 │
│ 10 │ 0.18299433892099454 │
│ 20 │ 0.22847255749045017 │
│ 30 │ 0.2037816688365288 │
│ 40 │ 0.1987063517030308 │
│ 50 │ 0.17341406302829748 │
│ 60 │ 0.1808884776496144 │
│ 70 │ 0.18711773536450496 │
│ 80 │ 0.18905573684766458 │
│ 90 │ 0.2505147771581594 │
│ 100 │ 0.2427673990917429 │
│ 110 │ 0.19088569009169926 │
│ 120 │ 0.14218574654598348 │
│ 130 │ 0.20894252550489317 │
│ 140 │ 0.22316626978848397 │
│ 150 │ 0.1859507592277053 │
│ 160 │ 0.22007759757363546 │
│ 170 │ 0.20406936638195144 │
│ 180 │ 0.1412102467834332 │
│ 190 │ 0.20677550885049117 │
└─────────────┴─────────────────────┘
20 rows in set. Elapsed: 0.167 sec. Processed 15.07 million rows, 101.74 MB (90.51 million rows/s., 610.98 MB/s.)
Обнадеживающе, наш % комментариев достаточно стабилен и не ухудшается по мере внесения вклада автора.
Мы можем использовать тот же принцип, что и Список файлов, которые переписывались наибольшее количество раз или наибольшее количество авторов для идентификации переписываний, но учитывая все файлы. Оконная функция используется для вычисления времени между переписываниями для каждого файла. С этого мы можем рассчитать среднее и медиану по всем файлам.
play
WITH
changes AS
(
SELECT
path,
commit_hash,
max_time,
type,
num_added,
num_deleted,
sum(num_added - num_deleted) OVER (PARTITION BY path ORDER BY max_time ASC) AS current_size,
if(current_size > 0, num_added / current_size, 0) AS percent_add,
if(current_size > 0, num_deleted / current_size, 0) AS percent_delete
FROM
(
SELECT
path,
max(time) AS max_time,
commit_hash,
any(lines_added) AS num_added,
any(lines_deleted) AS num_deleted,
any(change_type) AS type
FROM git.file_changes
WHERE (change_type IN ('Add', 'Modify')) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY
path,
commit_hash
ORDER BY
path ASC,
max_time ASC
)
),
rewrites AS
(
SELECT
*,
any(max_time) OVER (PARTITION BY path ORDER BY max_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS previous_rewrite,
dateDiff('day', previous_rewrite, max_time) AS rewrite_days
FROM changes
WHERE (type = 'Modify') AND (percent_add >= 0.5) AND (percent_delete >= 0.5) AND (current_size > 50)
)
SELECT
avgIf(rewrite_days, rewrite_days > 0) AS avg_rewrite_time,
quantilesTimingIf(0.5)(rewrite_days, rewrite_days > 0) AS half_life
FROM rewrites
┌─avg_rewrite_time─┬─half_life─┐
│ 122.2890625 │ [23] │
└──────────────────┴───────────┘
1 row in set. Elapsed: 0.388 sec. Processed 266.05 тысяч строк, 22.85 MB (685.82 тысяч строк/с., 58.89 MB/с.)
Какое худшее время для написания кода с точки зрения высокой вероятности переписывания?
Похоже на Каково среднее время, прежде чем код будет переписан, и медиана (период полураспада кода)? и Список файлов, которые переписывались наибольшее количество раз или наибольшее количество авторов, за исключением того, что мы агрегируем по дню недели. Настройте по мере необходимости, например, по месяцу года.
play
WITH
changes AS
(
SELECT
path,
commit_hash,
max_time,
type,
num_added,
num_deleted,
sum(num_added - num_deleted) OVER (PARTITION BY path ORDER BY max_time ASC) AS current_size,
if(current_size > 0, num_added / current_size, 0) AS percent_add,
if(current_size > 0, num_deleted / current_size, 0) AS percent_delete
FROM
(
SELECT
path,
max(time) AS max_time,
commit_hash,
any(file_lines_added) AS num_added,
any(file_lines_deleted) AS num_deleted,
any(file_change_type) AS type
FROM git.line_changes
WHERE (file_change_type IN ('Add', 'Modify')) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY
path,
commit_hash
ORDER BY
path ASC,
max_time ASC
)
),
rewrites AS
(
SELECT any(max_time) OVER (PARTITION BY path ORDER BY max_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS previous_rewrite
FROM changes
WHERE (type = 'Modify') AND (percent_add >= 0.5) AND (percent_delete >= 0.5) AND (current_size > 50)
)
SELECT
dayOfWeek(previous_rewrite) AS dayOfWeek,
count() AS num_re_writes
FROM rewrites
GROUP BY dayOfWeek
┌─dayOfWeek─┬─num_re_writes─┐
│ 1 │ 111 │
│ 2 │ 121 │
│ 3 │ 91 │
│ 4 │ 111 │
│ 5 │ 90 │
│ 6 │ 64 │
│ 7 │ 46 │
└───────────┴───────────────┘
7 rows in set. Elapsed: 0.466 sec. Processed 7.54 million rows, 701.52 MB (16.15 million rows/s., 1.50 GB/s.)
Код каких авторов является самым «липким»?
Мы определяем "липкость" как то, как долго код автора остается до его переписывания. Аналогично предыдущему вопросу Каково среднее время, прежде чем код будет переписан, и медиана (период полураспада кода)? - используя тот же показатель для переписываний, т.е. 50% добавлений и 50% удалений из файла. Мы вычисляем среднее время переписывания для каждого автора и учитываем только участников с более чем двумя файлами.
play
WITH
changes AS
(
SELECT
path,
author,
commit_hash,
max_time,
type,
num_added,
num_deleted,
sum(num_added - num_deleted) OVER (PARTITION BY path ORDER BY max_time ASC) AS current_size,
if(current_size > 0, num_added / current_size, 0) AS percent_add,
if(current_size > 0, num_deleted / current_size, 0) AS percent_delete
FROM
(
SELECT
path,
any(author) AS author,
max(time) AS max_time,
commit_hash,
any(file_lines_added) AS num_added,
any(file_lines_deleted) AS num_deleted,
any(file_change_type) AS type
FROM git.line_changes
WHERE (file_change_type IN ('Add', 'Modify')) AND (file_extension IN ('h', 'cpp', 'sql'))
GROUP BY
path,
commit_hash
ORDER BY
path ASC,
max_time ASC
)
),
rewrites AS
(
SELECT
*,
any(max_time) OVER (PARTITION BY path ORDER BY max_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS previous_rewrite,
dateDiff('day', previous_rewrite, max_time) AS rewrite_days,
any(author) OVER (PARTITION BY path ORDER BY max_time ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS prev_author
FROM changes
WHERE (type = 'Modify') AND (percent_add >= 0.5) AND (percent_delete >= 0.5) AND (current_size > 50)
)
SELECT
prev_author,
avg(rewrite_days) AS c,
uniq(path) AS num_files
FROM rewrites
GROUP BY prev_author
HAVING num_files > 2
ORDER BY c DESC
LIMIT 10
┌─prev_author─────────┬──────────────────c─┬─num_files─┐
│ Michael Kolupaev │ 304.6 │ 4 │
│ alexey-milovidov │ 81.83333333333333 │ 4 │
│ Alexander Kuzmenkov │ 64.5 │ 5 │
│ Pavel Kruglov │ 55.8 │ 6 │
│ Alexey Milovidov │ 48.416666666666664 │ 90 │
│ Amos Bird │ 42.8 │ 4 │
│ alesapin │ 38.083333333333336 │ 12 │
│ Nikolai Kochetov │ 33.18421052631579 │ 26 │
│ Alexander Tokmakov │ 31.866666666666667 │ 12 │
│ Alexey Zatelepin │ 22.5 │ 4 │
└─────────────────────┴────────────────────┴───────────┘
10 rows in set. Elapsed: 0.555 sec. Processed 7.54 million rows, 720.60 MB (13.58 million rows/s., 1.30 GB/s.)
Наибольшее количество последовательных дней коммитов автором
Этот запрос сначала требует от нас вычислить дни, когда автор делал коммиты. Используя оконную функцию, разбивая по авторам, мы можем вычислить дни между их коммитами. Для каждого коммита, если время с последнего коммита составило 1 день, мы отмечаем это как последовательное (1), иначе - 0, сохраняя этот результат в consecutive_day.
Наши последующие массивные функции вычисляют самую длинную последовательность последовательных единиц для каждого автора. Сначала используется функция groupArray, чтобы собрать все значения consecutive_day для автора. Этот массив из 1s и 0s затем разбивается на подмассивы по значениям 0. Наконец, мы вычисляем самый длинный подмассив.
play
WITH commit_days AS
(
SELECT
author,
day,
any(day) OVER (PARTITION BY author ORDER BY day ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS previous_commit,
dateDiff('day', previous_commit, day) AS days_since_last,
if(days_since_last = 1, 1, 0) AS consecutive_day
FROM
(
SELECT
author,
toStartOfDay(time) AS day
FROM git.commits
GROUP BY
author,
day
ORDER BY
author ASC,
day ASC
)
)
SELECT
author,
arrayMax(arrayMap(x -> length(x), arraySplit(x -> (x = 0), groupArray(consecutive_day)))) - 1 AS max_consecutive_days
FROM commit_days
GROUP BY author
ORDER BY max_consecutive_days DESC
LIMIT 10
┌─author───────────┬─max_consecutive_days─┐
│ kssenii │ 32 │
│ Alexey Milovidov │ 30 │
│ alesapin │ 26 │
│ Azat Khuzhin │ 23 │
│ Nikolai Kochetov │ 15 │
│ feng lv │ 11 │
│ alexey-milovidov │ 11 │
│ Igor Nikonov │ 11 │
│ Maksim Kita │ 11 │
│ Nikita Vasilev │ 11 │
└──────────────────┴──────────────────────┘
10 rows in set. Elapsed: 0.025 sec. Processed 62.78 thousand rows, 395.47 KB (2.54 million rows/s., 16.02 MB/s.)
История коммитов файла построчно
Файлы могут быть переименованы. Когда это происходит, мы получаем событие переименования, где колонка path устанавливается в новый путь файла, а old_path представляет собой предыдущее местоположение, например:
play
SELECT
time,
path,
old_path,
commit_hash,
commit_message
FROM git.file_changes
WHERE (path = 'src/Storages/StorageReplicatedMergeTree.cpp') AND (change_type = 'Rename')
┌────────────────time─┬─path────────────────────────────────────────┬─old_path─────────────────────────────────────┬─commit_hash──────────────────────────────┬─commit_message─┐
│ 2020-04-03 16:14:31 │ src/Storages/StorageReplicatedMergeTree.cpp │ dbms/Storages/StorageReplicatedMergeTree.cpp │ 06446b4f08a142d6f1bc30664c47ded88ab51782 │ dbms/ → src/ │
└─────────────────────┴─────────────────────────────────────────────┴──────────────────────────────────────────────┴──────────────────────────────────────────┴────────────────┘
1 row in set. Elapsed: 0.135 sec. Processed 266.05 thousand rows, 20.73 MB (1.98 million rows/s., 154.04 MB/s.)
Это затрудняет просмотр полной истории файла, поскольку у нас нет единого значения, связывающего все изменения линий или файлов.
Чтобы решить эту проблему, мы можем использовать Пользовательские функции (UDF). В настоящее время они не могут быть рекурсивными, поэтому, чтобы определить историю файла, мы должны определить ряд UDF, которые вызывают друг друга явно.
Это означает, что мы можем отслеживать переименования на максимум до 5 уровней глубины - приведенный ниже пример имеет глубину 5. Маловероятно, что файл будет переименован больше раз, чем это, так что на данный момент этого достаточно.
CREATE FUNCTION file_path_history AS (n) -> if(empty(n), [], arrayConcat([n], file_path_history_01((SELECT if(empty(old_path), Null, old_path) FROM git.file_changes WHERE path = n AND (change_type = 'Rename' OR change_type = 'Add') LIMIT 1))));
CREATE FUNCTION file_path_history_01 AS (n) -> if(isNull(n), [], arrayConcat([n], file_path_history_02((SELECT if(empty(old_path), Null, old_path) FROM git.file_changes WHERE path = n AND (change_type = 'Rename' OR change_type = 'Add') LIMIT 1))));
CREATE FUNCTION file_path_history_02 AS (n) -> if(isNull(n), [], arrayConcat([n], file_path_history_03((SELECT if(empty(old_path), Null, old_path) FROM git.file_changes WHERE path = n AND (change_type = 'Rename' OR change_type = 'Add') LIMIT 1))));
CREATE FUNCTION file_path_history_03 AS (n) -> if(isNull(n), [], arrayConcat([n], file_path_history_04((SELECT if(empty(old_path), Null, old_path) FROM git.file_changes WHERE path = n AND (change_type = 'Rename' OR change_type = 'Add') LIMIT 1))));
CREATE FUNCTION file_path_history_04 AS (n) -> if(isNull(n), [], arrayConcat([n], file_path_history_05((SELECT if(empty(old_path), Null, old_path) FROM git.file_changes WHERE path = n AND (change_type = 'Rename' OR change_type = 'Add') LIMIT 1))));
CREATE FUNCTION file_path_history_05 AS (n) -> if(isNull(n), [], [n]);
Вызывая file_path_history('src/Storages/StorageReplicatedMergeTree.cpp'), мы рекурсируем через историю переименований, где каждая функция вызывает следующий уровень с old_path. Результаты объединяются с помощью arrayConcat.
Например,
SELECT file_path_history('src/Storages/StorageReplicatedMergeTree.cpp') AS paths
┌─paths─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ ['src/Storages/StorageReplicatedMergeTree.cpp','dbms/Storages/StorageReplicatedMergeTree.cpp','dbms/src/Storages/StorageReplicatedMergeTree.cpp'] │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
1 row in set. Elapsed: 0.074 sec. Processed 344.06 thousand rows, 6.27 MB (4.65 million rows/s., 84.71 MB/s.)
Мы можем использовать эту возможность, чтобы собрать коммиты для всей истории файла. В этом примере мы показываем один коммит для каждого из значений path.
SELECT
time,
substring(commit_hash, 1, 11) AS commit,
change_type,
author,
path,
commit_message
FROM git.file_changes
WHERE path IN file_path_history('src/Storages/StorageReplicatedMergeTree.cpp')
ORDER BY time DESC
LIMIT 1 BY path
FORMAT PrettyCompactMonoBlock
┌────────────────time─┬─commit──────┬─change_type─┬─author─────────────┬─path─────────────────────────────────────────────┬─commit_message──────────────────────────────────────────────────────────────────┐
│ 2022-10-30 16:30:51 │ c68ab231f91 │ Modify │ Alexander Tokmakov │ src/Storages/StorageReplicatedMergeTree.cpp │ fix accessing part in Deleting state │
│ 2020-04-03 15:21:24 │ 38a50f44d34 │ Modify │ alesapin │ dbms/Storages/StorageReplicatedMergeTree.cpp │ Remove empty line │
│ 2020-04-01 19:21:27 │ 1d5a77c1132 │ Modify │ alesapin │ dbms/src/Storages/StorageReplicatedMergeTree.cpp │ Tried to add ability to rename primary key columns but just banned this ability │
└─────────────────────┴─────────────┴─────────────┴────────────────────┴──────────────────────────────────────────────────┴─────────────────────────────────────────────────────────────────────────────────┘
3 rows in set. Elapsed: 0.170 sec. Processed 611.53 thousand rows, 41.76 MB (3.60 million rows/s., 246.07 MB/s.)
Нерешенные вопросы
Git blame
Это особенно сложно получить точный результат из-за невозможности в настоящее время сохранять состояние в массивных функциях. Это станет возможным с использованием arrayFold или arrayReduce, которые позволяют удерживать состояние на каждой итерации.
Приблизительное решение, достаточное для высокоуровневого анализа, может выглядеть примерно так:
SELECT
line_number_new,
argMax(author, time),
argMax(line, time)
FROM git.line_changes
WHERE path IN file_path_history('src/Storages/StorageReplicatedMergeTree.cpp')
GROUP BY line_number_new
ORDER BY line_number_new ASC
LIMIT 20
┌─line_number_new─┬─argMax(author, time)─┬─argMax(line, time)────────────────────────────────────────────┐
│ 1 │ Alexey Milovidov │ #include <Disks/DiskSpaceMonitor.h> │
│ 2 │ s-kat │ #include <Common/FieldVisitors.h> │
│ 3 │ Anton Popov │ #include <cstddef> │
│ 4 │ Alexander Burmak │ #include <Common/typeid_cast.h> │
│ 5 │ avogar │ #include <Common/ThreadPool.h> │
│ 6 │ Alexander Burmak │ #include <Common/DiskSpaceMonitor.h> │
│ 7 │ Alexander Burmak │ #include <Common/ZooKeeper/Types.h> │
│ 8 │ Alexander Burmak │ #include <Common/escapeForFileName.h> │
│ 9 │ Alexander Burmak │ #include <Common/formatReadable.h> │
│ 10 │ Alexander Burmak │ #include <Common/thread_local_rng.h> │
│ 11 │ Alexander Burmak │ #include <Common/typeid_cast.h> │
│ 12 │ Nikolai Kochetov │ #include <Storages/MergeTree/DataPartStorageOnDisk.h> │
│ 13 │ alesapin │ #include <Disks/ObjectStorages/IMetadataStorage.h> │
│ 14 │ alesapin │ │
│ 15 │ Alexey Milovidov │ #include <DB/Databases/IDatabase.h> │
│ 16 │ Alexey Zatelepin │ #include <Storages/MergeTree/ReplicatedMergeTreePartheckout er.h> │
│ 17 │ CurtizJ │ #include <Storages/MergeTree/MergeTreeDataPart.h> │
│ 18 │ Kirill Shvakov │ #include <Parsers/ASTDropQuery.h> │
│ 19 │ s-kat │ #include <Storages/MergeTree/PinnedPartUUIDs.h> │
│ 20 │ Nikita Mikhaylov │ #include <Storages/MergeTree/MergeMutateExecutor.h> │
└─────────────────┴──────────────────────┴───────────────────────────────────────────────────────────────┘
20 rows in set. Elapsed: 0.547 sec. Processed 7.88 million rows, 679.20 MB (14.42 million rows/s., 1.24 GB/s.)
Мы приветствуем точные и улучшенные решения здесь.
Связанный контент